






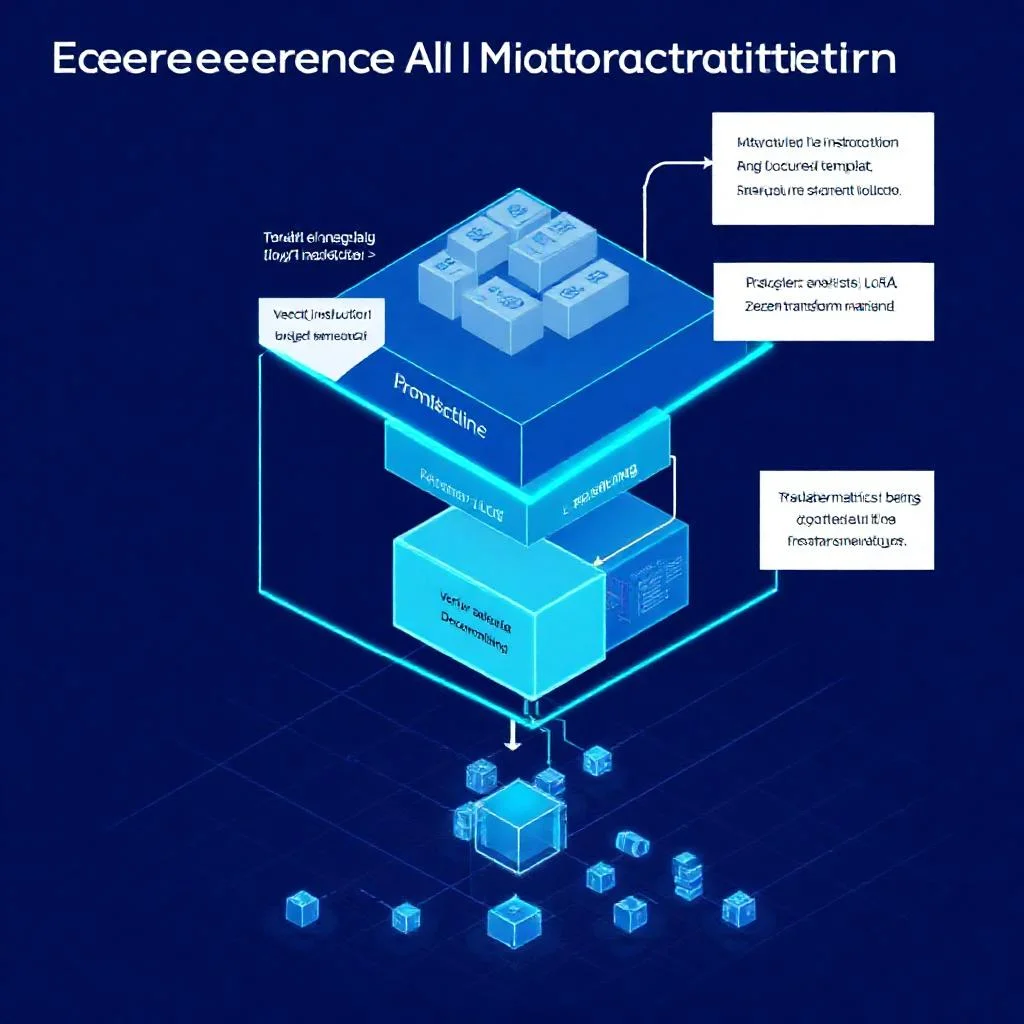
Fine-tuning, RAG ve prompt engineering ne zaman tercih edilmeli? Karar matrisi, maliyet karşılaştırması ve hibrit yaklaşımlar.

Gartner 2026 Conversational AI Magic Quadrant raporuna göre kurumsal chatbot platformları, müşteri hizmetleri operasyonlarının ortalama %47’sini otomatize ediyor ve birinci seviye destek maliyetlerini %41 azaltıyor; ancak başarılı projelerin oranı hâlâ %52’de kalıyor. Türkiye’de 2026 itibariyle banka, telekom, e-ticaret ve sağlık sektörlerinde 1.840’tan fazla kurumsal chatbot projesi üretimde olmakla birlikte, McKinsey State of Customer Operations 2026 […]

Gartner Search GenAI Impact 2026 raporuna göre kurumsal arama trafiğinin %38’i 2026 sonunda ChatGPT Search, Google AI Overviews, Perplexity, Gemini Deep Research ve Claude üzerinden akacak; BrightEdge Generative AI Index ise aylık ortalama 1,2 milyar AI yanıtının markaları “kaynak” olarak gösterdiğini belgeliyor. Klasik SEO’nun yerini almayan ama yanına eklenen Generative Engine Optimization (GEO), markaların yapay […]

Kurumsal RAG sistemi nasıl kurulur? Vector DB karşılaştırması, embedding modelleri, LangChain vs LlamaIndex ve KVKK uyumlu üretime alma adımları.

Kurumsal yapay zeka entegrasyonu için 2026 mimari seçimleri, maliyet analizi, 12 haftalık roadmap, sektörel adaptasyon ve ROI hesaplaması — RAG, fine-tuning ve agentic AI karşılaştırması.
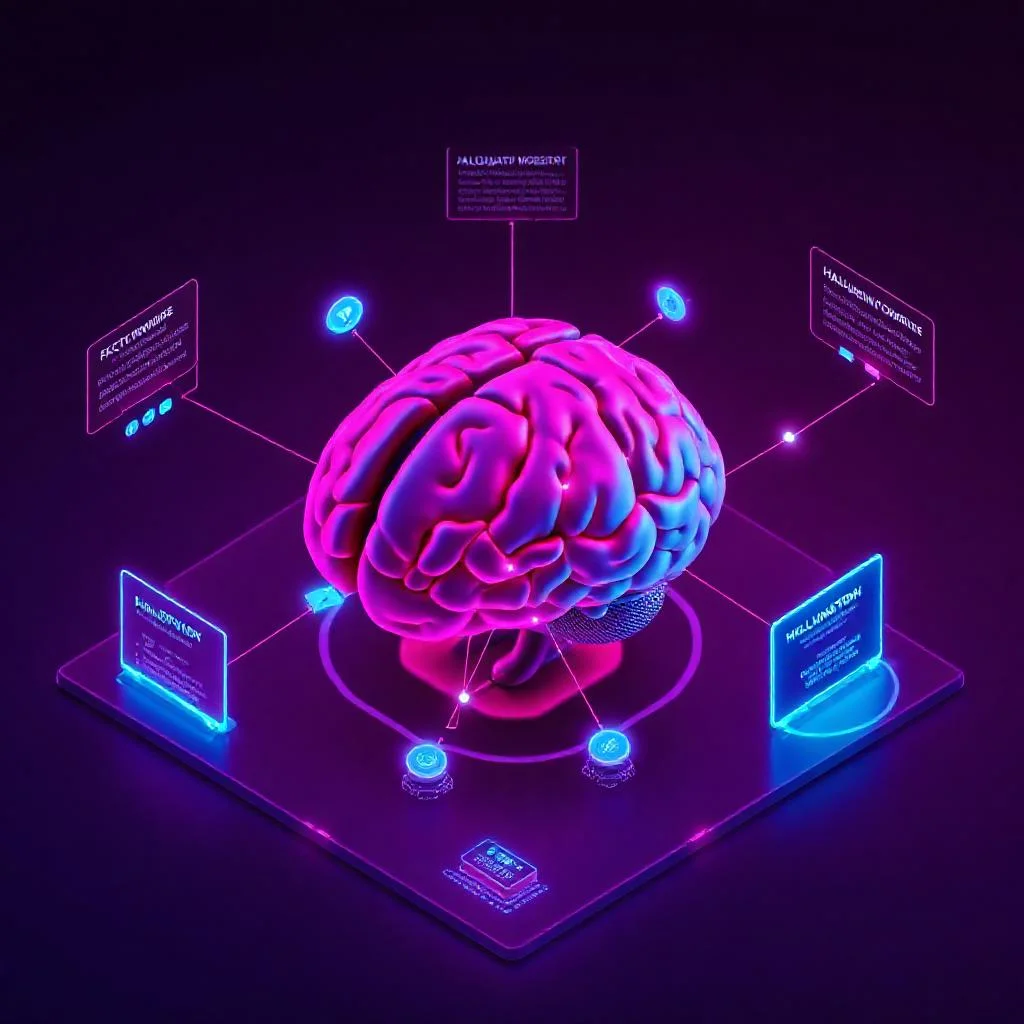
Stanford HELM 2026 değerlendirmesine göre kurumsal LLM dağıtımlarının %63’ünde hallucination (uydurma yanıt) oranı %8’in üzerinde kalıyor; finansal hizmetler ve sağlık gibi düzenlemeli sektörlerde bu oran %1 altına indirilmediğinde üretime alım onayı verilmiyor. Hugging Face Open LLM Leaderboard 2026 ölçümlerinde TruthfulQA skoru %50 altındaki modeller artık “yüksek risk” etiketiyle işaretleniyor; OpenAI Evals telemetrisi 2026 Şubat sürümünde […]
- 1
- 2