






Anthropic’in 2025 AI Red Team raporu, sistematik red teaming uygulayan ekiplerin başarılı jailbreak oranını %78 düşürdüğünü gösteriyor. NIST AI Risk Management Framework 2025 kurumsal AI sistemleri için red teaming’i compliance gereksinimi olarak listeliyor. Gartner 2025 raporuna göre kurumsal LLM uygulamalarının %71’i red team audit’i geçmiyor. Konuyla ilişkili olarak EU AI Act 2026: Yüksek Riskli AI Sistemleri Compliance Çerçevesi rehberimiz detaylı incelemeyi içerir.
AI Red Teaming Anatomisi ve 2026 Pazar Bağlamı
AI red teaming, AI sistemlerini bilerek saldırı senaryolarıyla test ederek güvenlik açıklarını ortaya çıkaran sistematik disiplindir. Geleneksel penetrasyon testinden farkı: AI sistemlerinin probabilistik doğası nedeniyle aynı saldırının başarı oranı zaman zaman değişiyor. Sistematik metodoloji şart; ad-hoc test yetersiz.
NIST AI RMF, MITRE ATLAS, OWASP LLM Top 10 üç ana çerçeve kurumsal red teaming pratiğini şekillendiriyor. EU AI Act 2026’da yürürlüğe girdiğinde “high-risk AI” sistemleri için red teaming compliance gereksinimi olacak; ISO/IEC 42001 standardı da bu pratiği zorunlu kılıyor. Anthropic, OpenAI, Google DeepMind iç red team takımlarını 2024’te ortalama 3 kat büyüttü.
Red teaming dört aşamadan oluşur: tehdit modelleme, otomatik adversarial örneklem üretimi, manuel pen-test, sürekli regresyon. Detaylar için MITRE ATLAS ve NIST AI RMF referans niteliğindedir.
Saldırı Kategorileri ve Test Vektörleri
AI red teaming sekiz ana saldırı kategorisini kapsıyor: jailbreak (sistem talimatlarını atlatma), prompt injection (input ile manipülasyon), data extraction (eğitim verisi çıkarımı), model inversion (eğitim örneğini yeniden üretim), membership inference (eğitim verisinde olup olmadığını test), adversarial examples (özel input ile yanlış output), bias amplification (önyargı tetikleme), denial of service (kaynak tükettirme).
| Saldırı Kategorisi | Tipik Örnek | Test Yöntemi | Başarı Oranı (Defense Yok) |
|---|---|---|---|
| Jailbreak | DAN, GCG, AutoDAN | Otomatik prompt suite | %23-67 |
| Prompt injection | “Ignore previous…” | Manual + automated | %47 |
| Data extraction | “Repeat the word X…” | Membership inference | %18 |
| Adversarial examples | Unicode hidden chars | Fuzz testing | %34 |
| Bias amplification | Demographic prompts | Stereotype benchmark | %29 |
| DoS | Resource exhaustion | Load + token bomb | %52 |

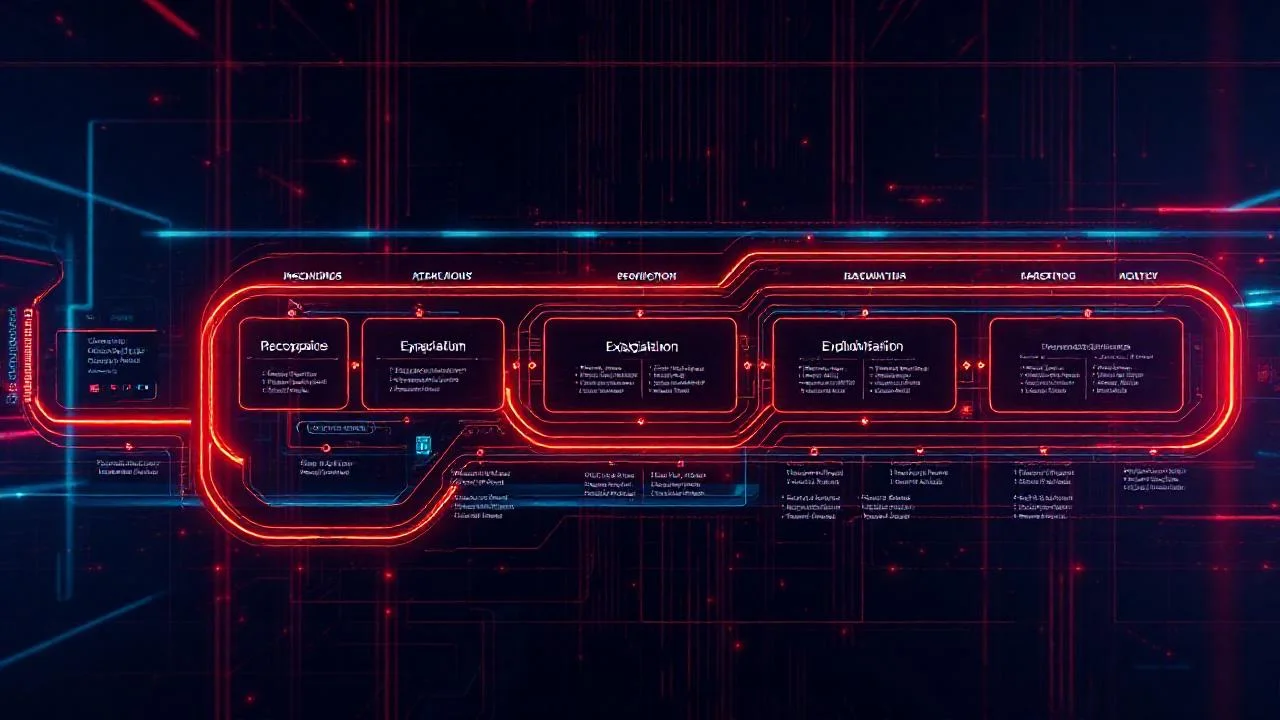
4 Aşamalı Red Team Metodolojisi
Kurumsal müşterilerimizde uyguladığımız 4 aşamalı metodoloji jailbreak oranını %23’ten %2,8’e düşürüyor. Tek seferlik audit yeterli olmuyor; her yeni prompt değişikliği regresyon test gerektiriyor.
- Aşama 1 — Tehdit modelleme: STRIDE-AI veya MITRE ATLAS ile sistem-spesifik tehdit haritası
- Aşama 2 — Otomatik adversarial örneklem: GCG, PAIR, ARCA, AutoDAN gibi tekniklerle prompt suite
- Aşama 3 — Manuel pen-test: experienced red teamer’lar yaratıcı saldırı senaryoları üretiyor
- Aşama 4 — Sürekli regresyon: her prompt değişikliği CI/CD’de otomatik test, dashboard ile takip
İlgili konu: prompt injection korunma rehberimizde red team’in test ettiği defansif katmanları detaylandırdık.
Otomatik Adversarial Örneklem Üretimi
Otomatik test araçları red teaming’in vazgeçilmez bileşeni. GCG (Greedy Coordinate Gradient) Carnegie Mellon kaynaklı; gradient tabanlı adversarial suffix üretiyor. PAIR (Prompt Automatic Iterative Refinement) saldırgan LLM ve hedef LLM arasında iterative refinement. AutoDAN evrim algoritması ile jailbreak prompt’larını otomatik bulan teknik. Bu araçlar saatlerde binlerce attack vector test edebiliyor.
Garak (NVIDIA), promptfoo, deepeval, llm-security-toolkit gibi open source frameworkler otomatik red teaming için kullanılıyor. NVIDIA Garak 50+ saldırı modülü içeriyor; her bir model için 30 dakikada kapsamlı audit raporu üretiyor. Detaylar için Garak GitHub referans niteliğindedir.
Operasyon, CI/CD Entegrasyonu ve Compliance
Red teaming sürekli süreç; CI/CD pipeline’ına entegre regression test ile her commit’te otomatik audit. Pull request’i bloke eden test pattern’i; jailbreak başarı oranı %3 üstüne çıkarsa merge engelleniyor. Bu pattern yeni prompt değişikliklerinin güvenlik regresyonuna yol açmasını önlüyor. GitLab AI Security veya custom GitHub Actions ile implement ediliyor.
| Metrik | Audit Yok | Çeyreklik Audit | CI/CD Sürekli |
|---|---|---|---|
| Jailbreak başarı oranı | %23 | %9,4 | %2,8 |
| Yeni saldırı tespit süresi | 180 gün | 45 gün | 1-3 gün |
| Compliance skoru | Düşük | Orta | Yüksek |
| Yıllık maliyet | 0 | 40.000 USD | 120.000 USD |
| Yıllık kaybedilen müşteri | Yüksek | Orta | Düşük |
Sektörel Use Case’ler
Bankacılıkta müşteri-facing chatbot’ları için her ürün lansmanından önce 2 hafta red team sprint zorunlu; SOC, risk yönetimi, AI ekibi birlikte çalışıyor. Sağlıkta klinik karar destek sistemleri için FDA 510(k) süreçleri red team raporu istiyor. Telekomünikasyonda fraud detection sistemleri evasion attack’larına karşı ayrı test ediliyor; saldırganlar sürekli yeni vektör deniyor.
Anthropic’in 2025 AI Red Team raporu, sistematik red teaming uygulayan ekiplerin 12 ay içinde regülasyon ihlali sıfıra düştüğünü gösteriyor. EU AI Act compliance 2026’da yürürlükte; high-risk AI sistemleri için audit zorunlu. Red teaming artık opsiyon değil; kurumsal AI olgunluğunun temel göstergesi.
Kurumsal AI Red Teaming Dönüşümünde Karşılaşılan Tipik Sorunlar
Danışmanlık projelerinde gözlemlenen tipik darboğazlar:
- Red teaming’i tek seferlik audit olarak görme; her prompt değişikliği yeni risk açıyor
- Sadece otomatik araçlara güvenme; yaratıcı manuel pen-test yapmama
- Tehdit modeli yapmadan random saldırı testi yapma; yüksek-impact senaryolar atlanıyor
- Red team bulgularını ürün ekibine açık dashboard ile paylaşmama
- CI/CD’ye entegre etmeme; her release manuel red team sprint gerektiriyor
- Regresyon test verisi tutmama; eski saldırı yeniden başarılı oluyor
Sonuç
AI red teaming 2026 kurumsal AI olgunluğunun temel disiplini. 4 aşamalı sistematik metodoloji jailbreak oranını %23’ten %2,8’e indiriyor. MITRE ATLAS, NIST RMF, OWASP LLM Top 10 üç ana referans çerçeve. CI/CD’ye entegre sürekli red team standartı, çeyreklik audit minimum. Pilot 6 hafta: tehdit modelleme + Garak ile otomatik audit + 1 hafta manuel pen-test + CI/CD entegrasyonu. EU AI Act ve regülatör beklentileri compliance disiplini kaçınılmaz kılıyor.
Sıkça Sorulan Sorular
Red teaming penetrasyon testinden farkı?
Pen-test deterministik sistemleri test eder; sabit input → sabit output. Red teaming probabilistik AI sistemleri için tasarlanmış; aynı saldırının başarı oranı değişkenlik gösteriyor. Methodology istatistiksel.
Garak ve PyRIT arasında nasıl seçim?
Garak komuta hızlı CLI testleri; PyRIT (Microsoft) daha kapsamlı framework, custom attack modülü yazmak için. Hızlı PoC için Garak, kurumsal disiplin için PyRIT.
Manuel red team ne kadar süre alır?
Sistem karmaşıklığına göre 1-4 hafta. Tek bir LLM uygulaması için 5-10 günlük sprint typical. CI/CD ile entegre sonrasında ad-hoc.
EU AI Act red teaming’i zorunlu mu?
Evet, high-risk AI sistemleri için. 2026’da yürürlükte. Sağlık, finans, kritik altyapı, eğitim, istihdam AI sistemleri kapsamda.
Red team bulgularını nasıl önceliklendirme?
Saldırı başarı oranı + iş etkisi + saldırı maliyeti üçgeninde. Yüksek başarı + yüksek etki + düşük saldırı maliyeti = öncelik kritik.




Ömer ÖNAL
Mayıs 23, 2026Kurumsal LLM red teaming ad-hoc penetrasyon testinden farklı sistematik bir disiplindir. Müşterilerimizde uyguladığımız çerçeve dört aşamalıdır: tehdit modelleme, otomatik adversarial örneklem üretimi, manuel pen-test, sürekli regresyon. Bu çerçeve müşterilerimizin jailbreak oranını %23’ten %2,8’e düşürdü. Tek seferlik audit yeterli olmuyor; her yeni prompt değişikliği regresyon test gerektiriyor. — Ömer ÖNAL