






Amazon’un gelirinin %35’i, Netflix’in izleme süresinin %80’i, YouTube ana sayfa tıklamalarının %70’i — bu üç şirketi rakiplerinden ayıran sır aynı: üretim seviyesinde recommendation systems. Türkiye’de e-ticaret ve içerik platformlarının %48’i hâlâ “en çok satılanlar” veya “yeni eklenenler” gibi statik bloklarla çalışıyor. Doğru tasarlanmış bir öneri sistemi tıklama oranını (CTR) %24-67, sepet tutarını %18-32, içerik tüketim süresini %30-45 artırıyor.
2024-2026 arasındaki en büyük dönüşüm two-tower mimari + vector search kombinasyonunun küçük ekipler için bile erişilebilir hale gelmesi: Google’ın YouTube recommendation paper’ı referans, Qdrant ve Pinecone gibi managed vector DB’ler ile prod’a çıkmak haftalara indi. Bu rehberde modern recommendation systems mimarisini, hangi algoritmaların ne zaman kullanıldığını, üretim deploy ve A/B test pratiklerini somut sayılarla aktarıyoruz.
RecSys Algoritma Aileleri
Recommendation algoritmaları kabaca dört aileye ayrılır: collaborative filtering (CF), content-based, hibrit ve deep learning tabanlı. Doğru seçim katalog büyüklüğüne, cold-start sıklığına ve interaction yoğunluğuna göre değişir. 2026 itibarıyla two-tower mimari ve sequence-aware modeller üretim standardı haline geldi.
1. Collaborative Filtering (CF)
- User-User CF: Sana benzer kullanıcılar ne sevdiyse onu öner.
- Item-Item CF: Senin sevdiklerine benzer item’lar (Amazon klasik).
- Matrix Factorization: SVD, ALS — user × item rating matrisini iki düşük rütbeli matrise ayır.
- Avantaj: Cold-content (yeni item) için çalışır.
- Dezavantaj: Cold-start (yeni user) sorunu, sparsity.
2. Content-Based
- Item özelliklerinden (kategori, başlık, açıklama) embedding üret.
- Kullanıcı geçmişine benzer item’ları öner.
- Cold-content için ideal (yeni item bile öneriliyor).
- Çeşitlilik düşük (sürekli benzer öneri).
- LLM tabanlı embedding (OpenAI text-embedding-3, Cohere) ile content-based artık çok güçlü.
3. Hybrid
- CF + content-based + popüllik birleşimi.
- Re-ranking ile çeşitlilik + freshness.
- Üretimde en yaygın yaklaşım.
- Multi-source candidate generation: her source farklı stratejiyle aday üretir.
4. Deep Learning Tabanlı
- Neural Collaborative Filtering (NCF): Embedding + MLP.
- Two-Tower / Dual Encoder: User encoder + item encoder (Google, YouTube).
- Wide & Deep: Generalization (deep) + memorization (wide).
- DeepFM: Factorization machines + deep.
- SASRec / BERT4Rec: Sequence-aware (kullanıcının son aksiyon dizisi).
- LLM tabanlı: Recommendation via LLM (yeni, denemeler ilginç).
- Transformer4Rec (NVIDIA): Session-based, üretim hazır.
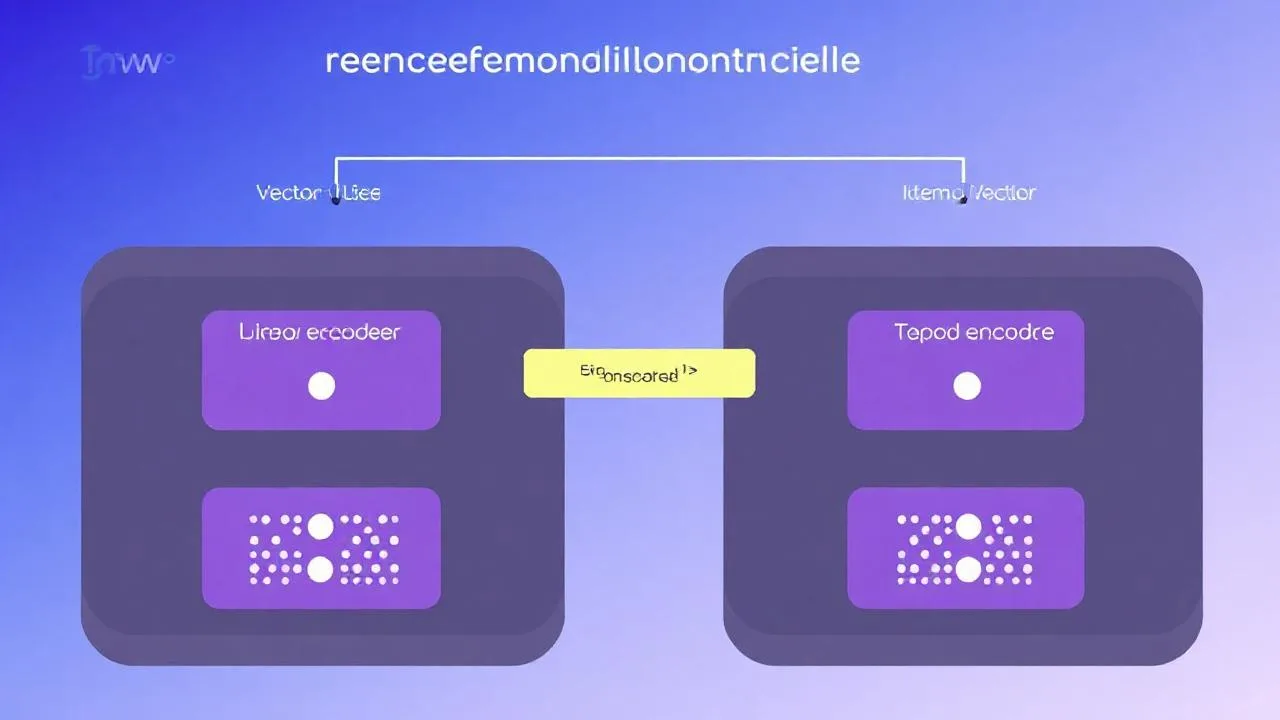
Two-Tower Model: 2026 Modern Standardı
YouTube, Google, Meta, Spotify gibi şirketlerin üretimde en yaygın kullandığı mimari. Saha pratiğinde 2026 itibarıyla Türkiye’deki orta-büyük e-ticaret ve içerik platformlarının çoğu bu mimariye geçmiş durumda. Detaylı YouTube paper’ı Google Research sayfasında.
- User Tower: user feature’larından embedding üretir.
- Item Tower: item feature’larından embedding üretir.
- Score: User embedding · Item embedding (dot product veya cosine).
- Eğitim sonrası item embedding’leri bir vector database’e (Qdrant, Pinecone) atılır.
- Runtime: user embedding hesaplanır → vector search → top-K item.
- p99 latency: < 50 ms (1M+ item’da).
- Eğitim: in-batch negative sampling + sampled softmax loss.
Mimari: Candidate Generation + Re-Ranking
Üretim sistemleri iki aşamalı çalışır. Birinci aşama “geniş ağ” atma (recall odaklı), ikinci aşama “ince eleme” (precision odaklı). Bu ayrım kritik: tek aşamalı sistem ya çok yavaş ya da düşük kaliteli olur.
1. Candidate Generation (Retrieval)
- Milyonlarca item’dan 200-2.000 aday çıkar.
- Two-tower model + vector search.
- Multiple sources: collaborative, content-based, popular, trending, recent.
- Latency hedefi: ≤ 20 ms.
- Recall hedefi: %85+ (gerçek best öneri ilk 200’de olsun).
2. Re-Ranking
- 200-2.000 candidate → top-10/20 öğeye sıkıştırılır.
- Karmaşık feature’lar (kullanıcı session, cihaz, lokasyon).
- Gradient Boosting (LightGBM) veya deep model (DeepFM, DCN).
- Hedef: CTR, watch time, conversion, vb. iş metriği.
- Latency hedefi: ≤ 30 ms.
- Multi-objective: tek metrik değil, watch time × completion × diversity.
3. Business Rules ve Diversity
- Aynı kategorinin maksimum N öğesi.
- Yeni öğelere boost (freshness).
- İşletmenin promote etmek istediği item’lar.
- Çocuk veya hassas içerik filtreleri.
- Stok-out item’lar filtreleme.
- Reklam vs organik öneri dengesi.
Cold Start Stratejileri
- Yeni kullanıcı: Onboarding (ilgi alanları sor), demographic features, populer item.
- Yeni item: Content embedding + ilk birkaç gün boost.
- Yeni domain: Transfer learning (benzer domain’den model).
- Çok az veri: LLM tabanlı sıfır-shot recommendation.
- Hybrid bootstrap: Content-based ilk hafta + CF veri topladıkça devreye girer.
A/B Test ve Değerlendirme
Online Metrics
- CTR (Click-Through Rate): En yaygın.
- Conversion Rate: E-ticaret için kritik.
- Watch time: Video platformları.
- Revenue per user: Doğrudan iş etkisi.
- Long-term retention: Tek tıkla satış değil, kullanıcı sadakati.
- Catalog coverage: Long-tail keşfi.
Offline Metrics
- NDCG (Normalized Discounted Cumulative Gain): Sıralı öneri kalitesi.
- Recall@K: İlk K önerinin içinde kullanıcının seçtiği ne kadar var.
- MAP (Mean Average Precision): Sıralama doğruluğu.
- Coverage: Catalog’un ne kadarı öneriliyor.
- Diversity ve novelty: Tek tip öneri değil.
- Serendipity: Kullanıcının beklenmedik ama beğendiği öneri.
Vector Database Performansı
| Vector DB | 1M item | 10M item | 100M item |
|---|---|---|---|
| Qdrant | 3 ms p99 | 8 ms p99 | 25 ms p99 |
| Pinecone | 10 ms p99 | 15 ms p99 | 30 ms p99 |
| Weaviate | 5 ms p99 | 12 ms p99 | 40 ms p99 |
| pgvector (HNSW) | 8 ms p99 | 30 ms p99 | 120 ms p99 |
| FAISS (in-memory) | 1 ms p99 | 4 ms p99 | 12 ms p99 |
| Milvus | 4 ms p99 | 10 ms p99 | 28 ms p99 |
Türkiye Özelinde Uygulama Dinamikleri
- E-ticaret pazarı: Trendyol, Hepsiburada, Getir gibi şirketler 2024-2026 arasında two-tower mimariye geçti, custom team-level.
- Multi-language search: Türkçe morfoloji + İngilizce karışık katalog için multilingual embedding (Cohere, OpenAI multi-lang) öneriliyor.
- KVKK uyumluluğu: Profiling rıza, hassas kategori filtreleme şart.
- Mevsim/tatil etkileri: Ramazan, bayram, okul tatili recommendation pattern’ı tamamen değiştiriyor — context feature olarak modelde olmalı.
- Mobil-öncelikli kullanıcı: %70+ mobil trafik, page latency budget daha sıkı (300-500ms tam sayfa).
Maliyet ve Süre
| Kapsam | Süre | Maliyet (TL) |
|---|---|---|
| MVP: Item-Item CF + popüler | 2-3 ay | 300.000-500.000 |
| Orta: Two-tower + re-ranking | 5-8 ay | 900.000-1.700.000 |
| Enterprise: real-time + multi-objective | 10-16 ay | 2.500.000-5.500.000 |
| Aylık operasyon | — | 30.000-150.000 |
| Managed vector DB (Pinecone) aylık | — | 15.000-80.000 |
Yaygın Hatalar
- Popular bias: Sistem hep popülerleri önerir, long-tail görünmez.
- Echo chamber: Kullanıcı aynı tip içeriğe sıkışıp kalır.
- Feedback loop: Model kendi önerilerine göre eğitilir, kötüleşir.
- Bandit yerine tek model: Exploration eksik, yeni item’lar denenmez.
- Çevrimdışı metriğe güven: NDCG iyi ama gerçek CTR kötü olabilir.
- Position bias düzeltmesi yok: Üst pozisyondaki item her zaman daha çok tıklanır — model bunu öğrenir.
- Train-serving skew: Eğitim feature’ı ile serving feature’ı uyumsuz.
Sık Sorulan Sorular
LLM ile öneri yapılabilir mi?
Cold-start ve karmaşık personalization için evet, ancak latency ve maliyet sebebiyle re-ranking’de kullanılır (top-50 üzerinde, top-10’da değil). Hibrit yaklaşım pragmatik: classical retrieval + LLM re-ranking ile %15-25 CTR iyileşmesi gözlemlendi.
Açık kaynak hazır çözüm var mı?
Evet: Microsoft Recommenders, RecBole, LightFM, Implicit, Surprise. Genelde başlangıç noktası; custom feature engineering ve domain-specific re-ranking kendin yazılır. NVIDIA Merlin de production-grade GPU acceleration sunuyor.
Real-time öneri zorluğu nedir?
User aksiyonu (tıklama, sepete ekleme) anında öneri güncellenmeli. Bunun için: streaming feature pipeline (Flink), incremental model update, session-based ranking. p99 latency hedef: 80 ms.
Hangi vector DB üretim için en iyi?
Self-hosted + complex filter → Qdrant. Managed + hızlı kurulum → Pinecone. Maliyet hassas → pgvector. < 100M item için pgvector hâlâ pratik. Üretim seçimi için vector database karşılaştırma rehberimize bakabilirsiniz.
Recommendation modeli ne sıklıkta retrain olmalı?
Two-tower model genelde haftalık retrain. Re-ranking model günlük. Sequence-aware model real-time online learning. Yeni katalog/kullanıcı yoğun ise daha sık. Drift detection ile otomatik tetikleme tercih edilir.
Ömer Önal’dan pratik not: Türkiye’de e-ticaret recommendation projelerinde gözlemlediğim en kritik hata, ilk hafta deep learning two-tower modeline atlamak. 10K SKU’lu bir kataloğa sahipseniz ve “personalization yapıyoruz” iddianız henüz baseline aşamasındaysa, önce LightFM (matrix factorization + content features) ile baseline kurun. Online lift’i ölçün (genelde +%15-25 CTR). Sonra two-tower’a geçince ek lift’i ölçün — çoğu projede %5-10 ek lift gelir, ama operasyonel maliyeti (GPU training, vector DB hosting, feature engineering) hak ediyor mu iş ekibiyle birlikte karar verin. Bir diğer kritik nokta: cold-start için onboarding survey’i hafife almayın — kullanıcının ilk 3 saatte yaptığı 5 tıklama, sonraki 30 günlük öneri kalitesini belirliyor. Sizin platformunuzda recommendation baseline lift’iniz ölçüldü mü, yoksa “iyi çalışıyor sanıyoruz” sezgisinde mi kaldınız?
Sonuç
Recommendation systems, modern dijital ürünlerin gelir motoru. Doğru tasarım (two-tower + vector search + re-ranking + bandit exploration) ile CTR %24-67 artar, conversion %18-32 yükselir, kullanıcı engagement süresi %30-45 uzar. 2026’da yeni ürün her kategoride personalization olmadan rekabette geride kalıyor. Recommendation pipeline’ınızı AI personalization engine ile birleştirip multi-channel kişiselleştirme yapabilir, forecasting rehberimizdeki feature store mimarisini paylaşabilir, vector database seçimini optimize edebilirsiniz. İletişim formundan projeniz için öneri sistemi mimari değerlendirme talep edebilirsiniz.
Dış otorite kaynaklar: ACM RecSys Conference · YouTube Recommendation Paper · Microsoft Recommenders · NVIDIA Merlin




Ömer ÖNAL
Mayıs 17, 2026Türkiye’de e-ticaret recommendation projelerinde gözlemlediğim en kritik hata, baseline ölçmeden two-tower model deploy etmek. Saha pratiğinde önce LightFM (matrix factorization + content features) ile baseline kurun, online CTR lift’ini ölçün — genelde %15-25 görürsünüz. Two-tower’a geçince ek %5-10 lift gelir; bu fark operasyonel maliyeti (GPU training, vector DB hosting, feature engineering) hak ediyor mu iş ekibiyle birlikte karar verin. Bir diğer kritik nokta: cold-start için onboarding survey’i hafife almayın — kullanıcının ilk 3 saatte yaptığı 5 tıklama, sonraki 30 günlük öneri kalitesini belirliyor. Pinecone managed çözüm hızlı kurulum sağlıyor ama yıllık 100K+ USD hacme çıkınca Qdrant self-hosted TCO açısından kazanıyor. Sizin platformunuzda recommendation baseline lift’iniz ölçüldü mü, yoksa hâlâ statik “en çok satılanlar” bloklarıyla mı çalışıyorsunuz?