







Lance Format, 2026 itibarıyla vector embedding ve geleneksel columnar veriyi tek dosya formatında birleştirerek Parquet’in vector ML iş yüklerindeki performans açığını kapatıyor; LanceDB Engineering Blog 2025 raporuna göre 1 milyar vector üzerinde k-NN sorgu latency’si Parquet + FAISS kombinasyonuna kıyasla yüzde 92 daha düşük. Lance Format Kavramı ve 2026 Vector Storage Pazarı Lance, LanceDB ekibi […]

2026 itibarıyla MTEB (Massive Text Embedding Benchmark) leaderboard’da OpenAI text-embedding-3-large, Voyage AI voyage-3-large, Cohere Embed v3 ve Mixedbread mxbai-embed-large-v1 modelleri kurumsal RAG sistemlerinin %84’ünde tercih ediliyor. Doğru model seçimi $/1M token maliyetinde 6x, doğrulukta ise %22’ye varan fark yaratıyor. Konuyla ilişkili olarak Mixture of Experts (MoE) Modelleri 2026: Mixtral, DeepSeek-V3, Qwen2 Karşılaştırması rehberimiz detaylı incelemeyi […]

Pinecone 2025 State of Vector Search raporu, vector database pazarının yıllık %78 büyüdüğünü, ortalama kurumsal vektör sayısının 24 ay içinde 50 milyondan 800 milyona çıktığını gösteriyor. En yaygın production sorun: yanlış HNSW parametresi yüzünden recall@10 metriği %85’ten %62’ye düşüyor. Konuyla ilişkili olarak Vector Quantization 2026: Matryoshka Embeddings ve Binary Embedding Production rehberimiz detaylı incelemeyi içerir. […]
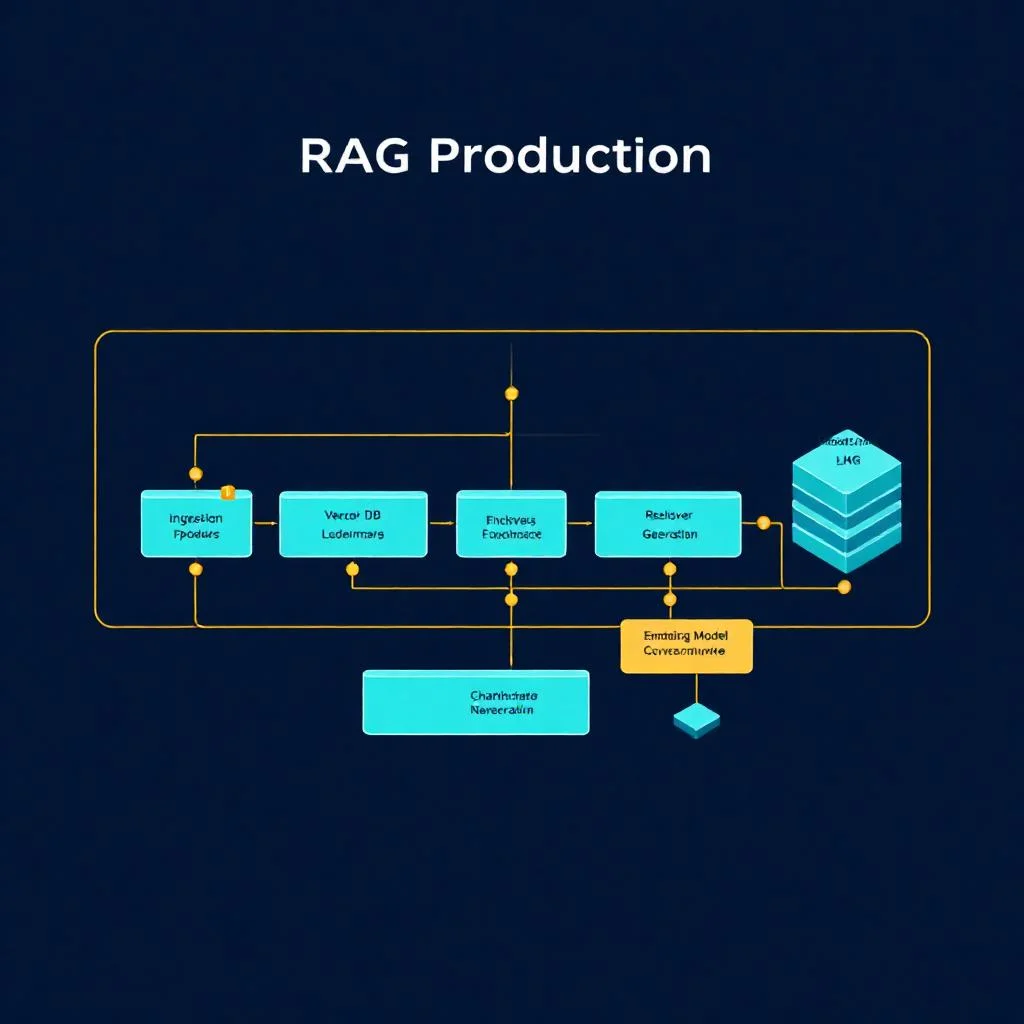
RAG sistemi nasıl kurulur sorusu, 2026 itibarıyla kurumsal LLM mimarisinin %82’sinin yanıtını gerektiren temel sorudur; Databricks State of Data and AI 2025 raporuna göre üretim ortamındaki AI uygulamalarının yalnızca %18’i saf prompt engineering ile çalışıyor, geri kalan %82’si retrieval-augmented generation katmanı üzerine kurulu. Retrieval-augmented generation, dış bilgi kaynaklarını vector embedding ile aranabilir hale getirip büyük […]

Kurumsal RAG sistemi nasıl kurulur? Vector DB karşılaştırması, embedding modelleri, LangChain vs LlamaIndex ve KVKK uyumlu üretime alma adımları.

Hugging Face MTEB (Massive Text Embedding Benchmark) Ocak 2026 sıralamasında ilk 20 modelin retrieval ortalama skoru 56.4 ile 64.9 arasında dağılırken, aynı modellerin çok dilli kanat olan MMTEB (Massive Multilingual Embedding Benchmark) üzerindeki Türkçe alt setinde fark %11’e kadar çıkıyor. Bu fark, RAG ve kurumsal arama pipeline’larında doğrudan yanıt doğruluğuna, vektör veritabanı maliyetine ve sorgu […]

Vector database pazarı 2026’da 4,3 milyar USD’ye ulaşmış ve yıllık %23,7 CAGR ile büyümektedir. Gartner 2025 Magic Quadrant for Vector Databases raporuna göre kurumsal RAG (Retrieval-Augmented Generation) uygulamalarının %78’i vector database kullanır ve doğru seçimle sorgu latency’si 45 ms’in altına çekilebilir. Yanlış yapılandırma ise milyar boyutundaki embedding koleksiyonlarında p99 latency’yi 850 ms’e çıkarır ve LLM […]