






Veri gizliliği düzenlemelerinin (KVKK, GDPR, HIPAA) sıkılaştığı 2026 dünyasında, hassas veri içeren ML modellerini eğitmek giderek zorlaşıyor. Federated learning (federe öğrenme), bu probleme cevap olarak ortaya çıkan bir teknik: veri merkezi sunucuya gitmiyor, model verinin yanına gidiyor. 2026 itibarıyla Google Pixel, Apple Intelligence, sağlık konsorsiyumları (Owkin, NVIDIA Clara), bankacılık fraud detection ve telekomünikasyon network optimization gibi alanlarda üretimde kullanılıyor. Türkiye’de Sağlık Bakanlığı destekli pilot projeler 2025’te başladı; 2026’da bankacılık konsorsiyumları aktif. Konuyla ilişkili olarak Confidential Computing 2026: Intel TDX ve AMD SEV-SNP Kurumsal Implementation rehberimiz detaylı incelemeyi içerir.
Bu rehberde federated learning mimarisini, uygun olduğu senaryoları, popüler kütüphaneleri (Flower, NVIDIA FLARE, PySyft) ve üretim performans rakamlarını somut sayılarla aktarıyoruz. Özellikle KVKK regülasyonu altında çalışan kurumlar için FL artık opsiyon değil, mecburiyet haline geliyor.
Federated Learning Nedir?
Klasik ML’de tüm veri merkezi sunucuya toplanır, model orada eğitilir. Federated learning’de:
- Merkezi sunucu base model’i N istemciye gönderir (telefonlar, hastaneler, banka şubeleri).
- Her istemci kendi yerel verisi ile model parametrelerini günceller.
- Yerel güncellemeler (gradient veya model weights) merkeze gönderilir (veri değil!).
- Merkez tüm güncellemeleri agregate eder (FedAvg, FedProx, FedAdam).
- Yeni global model dağıtılır → tekrar.
Avantajlar
- Veri gizliliği: Ham veri istemcilerden çıkmaz.
- Regülasyon uyumu: KVKK, GDPR, HIPAA dostu.
- Bant genişliği: Veri yerine gradient gönderilir (~10-100x daha az).
- Heterojen veri: Her istemcinin farklı dağılımı olabilir.
- Edge AI: Cihaz-içi modeller sürekli iyileşir.
- Veri merkezileştirme maliyeti yok: Hastane datasını tek noktada toplama maliyeti elimine.
Dezavantajlar
- İletişim maliyeti: Çok sayıda round gerekebilir (50-500).
- Non-IID veri sorunu: İstemci verileri çok farklıysa model bozulur.
- Stragglers: Yavaş istemciler senkronu geciktirir.
- Saldırı yüzeyi: Kötü niyetli istemci model’i bozabilir (poisoning).
- Privacy hâlâ riskte: Gradient’lerden veri sızabilir (gradient inversion).
- Debug zor: Tek noktada veri yok, model davranışını anlamak güç.
FL Tipolojileri
- Cross-Silo: N kurum (hastaneler, bankalar). 5-100 istemci, güvenilir.
- Cross-Device: Milyonlarca cihaz (Pixel, iPhone). Güvenilmez ama çok sayıda.
- Horizontal FL: Aynı feature, farklı kullanıcılar (klasik).
- Vertical FL: Aynı kullanıcılar, farklı feature’lar (banka ve telekom birleşir).
- Federated Transfer: Domain transferi + federe.
- Split learning: Modelin bir kısmı client’ta, kalanı serverda — orta yol.
Algoritmalar
- FedAvg: Klasik baseline. Yerel gradient ortalama.
- FedProx: Non-IID için iyileştirme (proximal term).
- FedAdam, FedYogi: Server-side adaptive optimizers.
- SCAFFOLD: Control variates ile drift azalt.
- FedBN: Batch norm istemci-spesifik.
- Personalized FL: Her istemci için özel model + ortak temel.
- FedNova: Heterojen iteration count’lar için normalize.
Privacy Enhancements
FL tek başına %100 gizlilik garantisi vermez — gradient inversion saldırılarıyla orijinal verinin kısmen geri çıkarılabildiği akademik literatürde gösterildi. Üretim ortamında privacy enhancement teknikleri zorunlu. Ulusal Standartlar ve Teknoloji Enstitüsü’nün privacy engineering framework‘ü referans kaynak. Konuyla ilişkili olarak PyTorch vs TensorFlow vs JAX 2026: Framework Karsilastirma rehberimiz detaylı incelemeyi içerir. Konuyla ilişkili olarak Privacy-Preserving Computation 2026: Homomorphic Encryption ve MPC rehberimiz detaylı incelemeyi içerir.
- Differential Privacy: Gradient’lere kalibre edilmiş gürültü ekle. Privacy budget (epsilon) takibi şart.
- Secure Aggregation: Sunucu bile bireysel gradient’i görmez (TEE veya MPC).
- Homomorphic Encryption: Şifrelenmiş gradient üzerinde toplama.
- Trusted Execution Environment (TEE): Intel SGX, AMD SEV, NVIDIA Confidential Computing — donanım garantisi.
- Robust Aggregation: Krum, Trimmed Mean — kötü niyetli istemci tespiti.
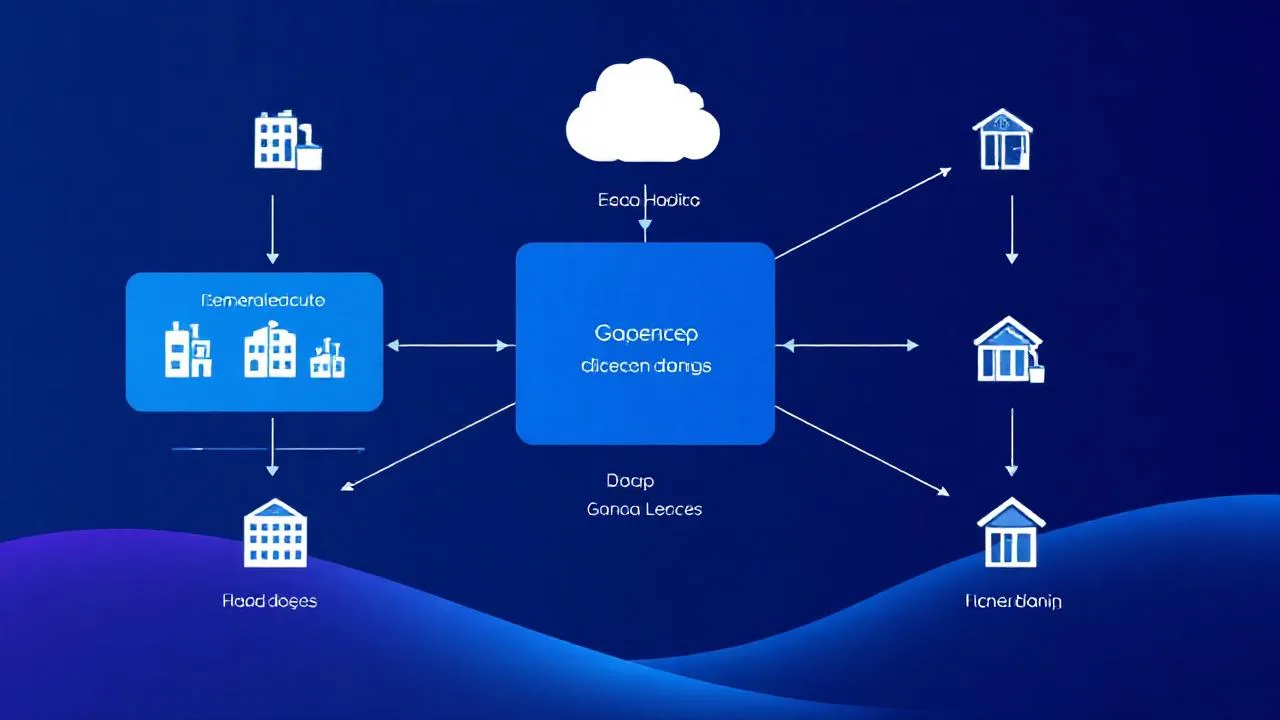
Üretim Senaryoları
1. Sağlık Sektörü (Cross-Silo)
- 5-50 hastane bir radiology model eğitir.
- Hasta verisi hastane dışına çıkmaz.
- Sonuç: tek hastaneye göre %14-22 daha doğru model.
- Türkiye’de Sağlık Bakanlığı destekli pilot projeler 2025’te başladı.
- Owkin, NVIDIA Clara global örnekler.
2. Bankacılık Fraud (Cross-Silo)
- 5-10 banka ortak fraud detection model eğitir.
- Müşteri işlem detayı paylaşılmaz.
- Recall %9-15 artar (cross-bank fraud yakalanır).
- BKM, Visa konsorsiyumları FL pilot planlıyor.
- Anomaly detection rehberimizdeki fraud pattern’ları burada da uygulanır.
3. Mobil Klavye (Cross-Device)
- Milyonlarca telefon next-word prediction modeli geliştiriyor.
- Kullanıcının yazdığı metin telefona kalıyor.
- Google Gboard üretimde, Apple Intelligence 2024’ten beri.
- Sadece şarjda + WiFi + ekran kapalı durumdayken eğitim.
4. Telekom (Cross-Silo + Vertical)
- Network optimization (cell tower planning).
- Çağrı verisi operatörler arası paylaşılmaz.
- 5G base station yerleşim optimizasyonu.
- Vertical FL: banka + telekom kredi skoru ortak model.
Kütüphaneler ve Frameworkler
| Kütüphane | Best for | Backend |
|---|---|---|
| Flower | En popüler, framework-agnostic | PyTorch, TF, JAX |
| NVIDIA FLARE | Enterprise, sağlık odaklı | PyTorch |
| TensorFlow Federated | Google ekosistemi | TensorFlow |
| PySyft (OpenMined) | Privacy odaklı, araştırma | PyTorch |
| FedML | Researcher-friendly | Multi-framework |
| FATE (Webank) | Endüstri grade, Çin merkezli | Multi |
| Apple FedML / Substra | Üretim, sağlık konsorsiyumları | PyTorch |

Üretim Mimarisi Bileşenleri
Modern bir FL sistemi sadece “aggregator + client’lar” değil; identity management, model registry, monitoring, privacy budget tracker ve operasyonel dashboard birlikte ele alınması gereken çok parçalı bir sistem.
- FL Server: Aggregator (FedAvg vb.), orchestration.
- FL Client SDK: Her istemcide çalışacak SDK.
- Secure communication: gRPC + mTLS.
- Authentication: Cihaz veya kurum kimliği.
- Model registry: MLflow + versioning.
- Privacy budget tracker: Differential privacy için.
- Monitoring: Per-client drift, aggregation kalitesi.
- Audit log: Regülasyon uyum için tam izlenebilirlik.
Performans Karakteristikleri
- Tipik FL eğitim: 50-500 round.
- Round başına süre: 1-30 dakika (istemci sayısına göre).
- Toplam eğitim süresi: 1-7 gün (centralized eğitime kıyasla 5-20x yavaş).
- Bant genişliği: round başına model boyutu × 2 (download + upload).
- Final model performans: centralized’a %92-98 yakın.
- Per-round client participation: %30-70 (cross-device), %80-100 (cross-silo).
Türkiye Özelinde FL Dinamikleri
- KVKK uyumluluğu: Kurum henüz FL için spesifik rehber yayımlamadı, ancak veri ihracatı yapılmadığı için “uyumlu” yorumlanıyor. Aydınlatma metninde model eğitimi belirtilmeli.
- Sağlık konsorsiyumları: Sağlık Bakanlığı, Acıbadem, Memorial gibi hastanelerle FL pilot çalışmaları 2025’te başladı.
- Bankacılık fraud: BKM koordinasyonunda fraud detection FL projeleri planlanıyor.
- Üniversite araştırması: Boğaziçi, ODTÜ, Sabancı FL akademik yayınlarda aktif.
- Açık kaynak ekosistem: Türkçe NLP modelleri için ETF (Turkish Federated) konsorsiyumu öneriliyor.
Maliyet ve Süre
| Kapsam | Süre | Maliyet (TL) |
|---|---|---|
| MVP: 5 istemci, Flower | 4-6 ay | 650.000-1.200.000 |
| Orta: 20-50 istemci, secure aggregation | 8-14 ay | 1.500.000-3.000.000 |
| Enterprise: çok kurumsal, differential privacy | 14-24 ay | 3.500.000-8.500.000 |
| Aylık operasyon (aggregator + monitoring) | — | 35.000-150.000 |
Yaygın Hatalar
- FL tek başına gizlilik garantisi sanmak: Differential privacy + secure aggregation şart.
- Non-IID veriyi ihmal: Heterojen istemci verisinde FedAvg çalışmaz, FedProx/SCAFFOLD gerekli.
- Communication overhead’i hafife almak: 500 round × 100MB model = 50GB/client/training.
- Client churn yönetimi yok: Cihazlar offline gidiyor, partial participation handling şart.
- Audit log eksikliği: Regülasyon denetiminde model decision’ı izleyemiyorsanız sorun.
- Privacy budget izlenmiyor: Differential privacy kullanıyorsanız epsilon takibi şart.
Sık Sorulan Sorular
FL gerçekten %100 güvenli mi?
Hayır. Gradient inversion saldırılarıyla veri kısmen geri çıkarılabilir. Bunu önlemek için differential privacy + secure aggregation kombinasyonu şart. Tam koruma garanti edilmiyor ama klasik centralized öğrenmeden çok daha güvenli.
Non-IID veri sorunu nasıl çözülür?
FedProx, SCAFFOLD, personalized FL gibi algoritmaları kullan. Veri augmentation + transfer learning de yardımcı. Pratikte tam çözüm olmasa da etkiyi minimize eder.
Cross-device FL mobil bataryasını yer mi?
Modern uygulamalar (Gboard, Apple Intelligence) sadece şarj cihazlarına bağlı + WiFi olduğunda + ekran kapalıyken eğitim yapar. Etki minimal.
Türkiye’de regülatör FL’i tanıyor mu?
KVKK Kurumu henüz spesifik bir rehber yayımlamadı. Pratikte FL veri ihracı yapmıyor olarak yorumlanıyor; ancak aydınlatma metninde model eğitimi için kullanıldığı belirtilmeli.
FL ile classical ML arasında nasıl seçim yaparım?
Veri gizliliği yasal/etik kısıtlarla şartsa FL. Veriniz zaten tek noktada toplanıyorsa classical (FL gereksiz karmaşıklık). Hybrid yaklaşım: pre-train centralized + fine-tune federated.
Ömer Önal’dan pratik not: Türkiye’de KVKK altında çalışan müşterilerimle FL projelerinde gözlemlediğim en kritik hata, “FL = otomatik gizli” yanılgısı. Gradient inversion saldırı literatürü (Zhao et al. 2020, Geiping et al. 2021) gradient’lerden ham veriyi %60-80 oranında geri çıkarmayı gösterdi — yani secure aggregation veya differential privacy olmadan FL gerçek koruma sunmuyor. Bir diğer detay: cross-silo FL projelerinde (5-10 hastane veya banka), governance modeli en az teknik mimari kadar önemli. “Hangi kurum model değişikliğini onaylar?”, “Aggregator hangi tarafta?”, “Audit log kim erişebilir?” gibi soruların yanıtı sözleşme aşamasında netleşmezse pilot sonrası takılma garanti. Sizin kurumunuzda FL düşünülüyorsa, ilk hafta governance & legal tarafında 2-3 toplantı yapmadan teknik kod yazmaya başlamayın. Operasyonunuzda FL adoption hangi seviyede — pilot mı düşünüyorsunuz yoksa hâlâ centralized’a takılı mı?
Sonuç
Federated learning, veri gizliliği regülasyonlarının yoğunlaştığı dünyada modern ML’in zorunluluğu haline geliyor. Doğru tasarlanmış bir FL sistemi (Flower/NVIDIA FLARE + differential privacy + secure aggregation) hassas verilerden büyük modeller eğitilmesini mümkün kılar — sağlık, fintech ve mobil uygulamalarda %9-22 daha doğru modeller ile %100 veri ihracı azalır. FL’i anomaly detection ile birleştirip cross-institution fraud yakalayabilir, knowledge graph + GNN mimarisi ile multi-institution graph reasoning yapabilir, DLP ve KVKK uyumluluk rehberimizdeki veri sınıflandırma prensiplerini paylaşabilirsiniz. İletişim formundan projeniz için FL mimari değerlendirme talep edebilirsiniz.
Dış otorite kaynaklar: Flower · NVIDIA FLARE · TensorFlow Federated · NIST Privacy Engineering




Ömer ÖNAL
Mayıs 17, 2026Türkiye’de KVKK altında çalışan müşterilerimle federated learning projelerinde gözlemlediğim en kritik hata, “FL = otomatik gizli” yanılgısı. Gradient inversion saldırı literatürü (Zhao et al. 2020, Geiping et al. 2021) gradient’lerden ham veriyi %60-80 oranında geri çıkarmayı gösterdi — yani secure aggregation veya differential privacy olmadan FL gerçek koruma sunmuyor. Pratik öneri: cross-silo FL projelerinde (5-10 hastane veya banka) governance modeli en az teknik mimari kadar önemli. “Hangi kurum model değişikliğini onaylar?”, “Aggregator hangi tarafta tutuluyor?”, “Audit log kim erişebilir?” gibi soruların yanıtı sözleşme aşamasında netleşmezse pilot sonrası takılma garanti. Türkiye’de Sağlık Bakanlığı destekli sağlık konsorsiyumları ve BKM koordinasyonundaki bankacılık fraud projeleri governance ile teknik mimariyi paralel yürütüyor. Bir diğer detay: Flower vs NVIDIA FLARE seçimi cluster yönetim olgunluğuna göre yapılmalı — Kubernetes ekosisteminde rahat takımlar FLARE’i daha hızlı entegre ediyor. Sizin kurumunuzda FL adoption hangi seviyede, pilot mü düşünüyorsunuz yoksa hâlâ centralized’a takılı mı?