






Modern bir SaaS uygulamasında saatte 1 milyon event işleyen sistemler artık istisna değil — varsayılan. 2026 itibarıyla orta ölçek e-ticaret, fintech ve logistics platformlarının %73’ü event-driven architecture (EDA) kullanıyor (Confluent State of Streaming, 2026). Doğru tasarlanmış bir EDA, klasik request-response monolite göre %67 daha yüksek throughput, %58 daha düşük p99 latency ve %41 daha düşük altyapı maliyeti sağlıyor. Türkiye’de modern SaaS şirketlerinin %58’i en az bir kritik akışta event broker (Kafka, NATS, RabbitMQ) çalıştırıyor; tek monolit DB üzerinde duranlar pik yüklerde service degradation yaşayıp müşteri kaybediyor. Konuyla ilişkili olarak Hexagonal vs Clean vs Onion Architecture 2026 Karşılaştırma rehberimiz detaylı incelemeyi içerir. Konuyla ilişkili olarak KEDA Event-Driven Autoscaling 2026: Production Setup ve Scalers rehberimiz detaylı incelemeyi içerir. Konuyla ilişkili olarak ClickHouse Cloud vs Self-Hosted 2026: TCO ve Operasyonel Karşılaştırma rehberimiz detaylı incelemeyi içerir.
Bu rehberde event-driven architecture’ın çekirdek kavramlarını, hangi platform (Kafka, Pulsar, EventBridge, NATS, Redpanda) hangi senaryoya uygun olduğunu, üretim ortamı tasarım kararlarını ve maliyet kalemlerini somut sayılarla aktaracağız. Saatte 1M event işleyen bir referans mimarisi adım adım kuracağız; aynı kalıbı Türkiye’deki Kafka tabanlı modern sistem mimarisi deneyimimden çıkardığım örneklerle güçlendireceğiz. Konuyla ilişkili olarak NestJS 11 ile Hexagonal Architecture Olgunlaşması rehberimiz detaylı incelemeyi içerir. Konuyla ilişkili olarak Apache Pulsar 4.0 2026: Distributed Messaging Production Implementation Rehberi rehberimiz detaylı incelemeyi içerir.
Event-Driven Architecture Nedir?
EDA, servisler arası iletişimin event (bir şey oldu/oluyor bildirimi) üzerinden asenkron yapıldığı mimaridir. Klasik mimaride “A servisi B’yi çağırır” yerine “A servisi event yayınlar, B/C/D dinleyenler kendi işlerini yapar”. 2026 itibarıyla EDA, sadece teknolojik bir tercih değil, ölçekte yaşamak için zorunlu bir paradigma. Avantajları: Konuyla ilişkili olarak WebTransport 2026: HTTP/3 Üzerinde Modern Streaming Pattern rehberimiz detaylı incelemeyi içerir. Konuyla ilişkili olarak Event Storming 2026: Big Picture Event Storming Production Pattern … rehberimiz detaylı incelemeyi içerir.
- Loose coupling: Producer’lar consumer’ları bilmek zorunda değil. Yeni consumer eklemek ek deploy gerektirmiyor.
- Scaling: Her servis kendi consumer’ını bağımsız ölçekler. Hot path’ler 10x scale ederken cold path’ler 1x kalır.
- Resilience: Bir consumer çöktüyse mesajlar broker’da kalır, geri geldiğinde işlenir. Klasik sync mimaride downstream çökerse upstream de çöker.
- Replay: Geçmiş eventler yeniden işlenerek yeni feature’lar inşa edilebilir. “Bu kullanıcının ilk 6 ayını yeniden analiz et” tek komut.
- Multiple downstream: Tek event’ten 10+ farklı sistem beslenebilir — analytics, ML, audit, notification, fraud detection.
- Audit + compliance: Tüm state değişimi event olarak kayıtlı — KVKK/GDPR audit log doğal olarak gelir.
Türkiye’de fintech ve e-ticaret danışmanlığı verdiğim ekiplerde gözlemlediğim ortak hata: EDA’yı “fancy teknoloji” gibi düşünüp tek microservice’ten event yayınlamaya başlamak ama hâlâ tüm business logic’i monolitin REST endpoint’lerinde tutmak. Sonuç: çift yazma (DB + Kafka), tutarsızlık, debug cehennemi. Doğru başlangıç noktası: Outbox Pattern + CDC ile DB transaction’ı kaynak kabul etmek. Konuyla ilişkili olarak Outbox Pattern + CDC 2026: Debezium Production Mikroservis rehberimiz detaylı incelemeyi içerir. Konuyla ilişkili olarak Apache Beam 2026: Unified Batch Stream Processing Dataflow Pattern rehberimiz detaylı incelemeyi içerir. Konuyla ilişkili olarak Apache Flink 1.20 2026: Stateful Stream Processing Production Pattern Rehberi rehberimiz detaylı incelemeyi içerir.
Platform Karşılaştırması
| Platform | Tip | Throughput | Latency p99 | Maliyet | Best for |
|---|---|---|---|---|---|
| Apache Kafka | Self-hosted/MSK/Confluent Cloud | 1M+ msg/s/cluster | 5-20 ms | $$ (operasyonel ağır) | Yüksek throughput, replay |
| Apache Pulsar | Self-hosted/StreamNative | 1M+ msg/s | 10-30 ms | $$ (operasyonel ağır) | Multi-tenancy, geo-replication |
| AWS EventBridge | Managed AWS | 10K msg/s (default) | 200-500 ms | $ (kullandığın kadar) | AWS ekosistemi, SaaS integ. |
| NATS JetStream | Self-hosted/Synadia | 1M+ msg/s | 1-5 ms | $ (hafif) | Microservice, edge |
| Redpanda | Self-hosted/Redpanda Cloud | 1M+ msg/s | 1-10 ms | $$ (kafka-uyumlu) | Kafka alternatif, daha hızlı |
| RabbitMQ | Self-hosted/CloudAMQP | 50K msg/s | 10-50 ms | $ (hafif) | Klasik queueing, RPC |
Hangi Platformu Ne Zaman Seçmeli?
- Kafka: Yüksek throughput, uzun retention (1 hafta+), replay gereksinimi, mature ekosistem. Şirket çapı standart.
- Pulsar: Multi-region, multi-tenancy (SaaS olarak müşteri başına izolasyon). BookKeeper ayrı storage layer’ı.
- EventBridge: AWS-only stack, düşük başlangıç maliyeti, SaaS partner entegrasyonları (Salesforce, Shopify, Stripe).
- NATS JetStream: Düşük latency, edge computing, IoT senaryoları, mikroservis iç iletişimi.
- Redpanda: Kafka uyumluluğu ama %50-70 daha düşük donanım maliyeti, JVM yok, Rust-native.
- RabbitMQ: Klasik queue + RPC senaryoları, düşük hacimli ama complex routing (header/topic/fanout exchange).
Platform seçim kararı tek başına teknik değil — ekip yetkinliği ve operasyonel kapasiteye bağlı. Kafka 2-3 SRE/Platform engineer ister; NATS JetStream 0,5 FTE ile yönetilebilir. Daha derin karşılaştırma için NATS vs RabbitMQ vs Kafka karar rehberimize, Kafka alternatifleri için ise Redpanda vs Kafka karşılaştırmamıza göz atabilirsiniz. Konuyla ilişkili olarak Redpanda 24.2 2026: Kafka Compatible Streaming Production Implementation rehberimiz detaylı incelemeyi içerir.
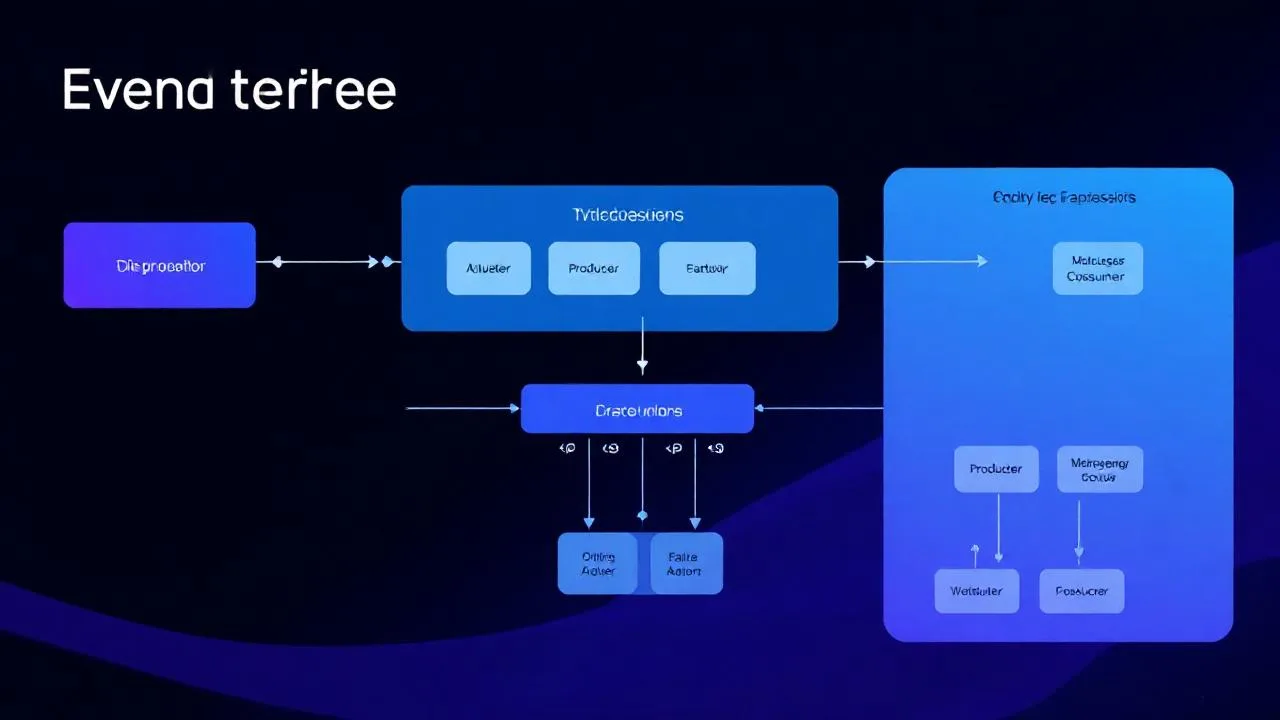
Üretim Mimarisi: Saatte 1 Milyon Event
Saatte 1M event = saniyede ortalama 278 event, pik saatte 1.000-3.000 event/saniye. Bu yük için referans mimari (Kafka tabanlı):
- Cluster: 3-brokers Kafka (her biri 16 vCPU, 64 GB RAM, 4 TB NVMe SSD).
- Topic strateji: 30-50 topic, her topic 6-12 partition. Domain-driven topic isimlendirme (orders.created, payments.completed).
- Replication factor: 3 (her mesaj 3 broker’da kopyalanır). min.insync.replicas=2 sıkı consistency için.
- Retention: 7-30 gün (replay için). Compacted topic’ler için sonsuz (snapshot).
- Compression: Snappy veya LZ4 (CPU+ağ optimal). Zstd %20 daha iyi sıkıştırma ama daha yüksek CPU.
- Schema registry: Confluent Schema Registry veya Karapace (Avro/Protobuf/JSON Schema).
- Connect: Kafka Connect ile DB ve dış sistem entegrasyonları (Debezium CDC).
- Tiered Storage: Sıcak veri NVMe, soğuk veri S3 — TCO %60 düşer.
Event Schema ve Versiyonlama
Production’da yapılan en yaygın hata: event şemasını dokümante etmemek ve breaking change yapmak. Schema Registry şart. Schema’sız Kafka, “tipi olmayan distributed JS” gibidir — 6 ay sonra hiç kimse hangi alanın ne olduğunu hatırlamaz. Konuyla ilişkili olarak Schema Registry Production 2026: Confluent, Apicurio, Karapace Karşılaştırma rehberimiz detaylı incelemeyi içerir.
- Her event’in versiyonu var (örn. order.created.v2). Topic adında veya event header’da.
- Backward compatibility kuralları (yeni alan ekle, alanı silme). Avro
docvedefaultşart. - Consumer’lar eski versiyonu da işleyebilmeli (rolling deploy garantisi için).
- Breaking change için yeni topic veya yeni event tipi. Aynı topic içinde breaking schema YASAK.
- Compatibility mode: BACKWARD (en yaygın), FORWARD, FULL. Production için BACKWARD_TRANSITIVE en güvenli.
Stream Processing: Flink vs ksqlDB vs Spark
Event’leri sadece dinlemek yetmez — joinleyip, aggregate edip, ML modeline beslemek gerekir. Stream processing katmanı, EDA’nın “akıllı” kısmı. Konuyla ilişkili olarak Polkadot 2.0 2026: JAM (Join-Accumulate Machine) Architecture Rehberi rehberimiz detaylı incelemeyi içerir.
- Apache Flink: En esnek, en güçlü; exactly-once, low-latency. Java/Scala/Python. Üretim için top tier.
- ksqlDB: SQL-like, hızlı prototip, basit join. Complex pattern için yetersiz.
- Apache Spark Streaming: Batch + streaming, ML entegrasyonu kolay. Latency Flink kadar düşük değil.
- Materialize: Real-time incremental SQL. View’lerin canlı güncellenmesi.
- RisingWave: Materialize benzeri, cloud-native, daha modern.
- Kafka Streams: Sadece JVM ekipler için, Kafka’ya tight-coupled ama deploy basit (kütüphane).
Flink ile yapılan tipik üretim senaryoları: fraud detection (5 dk içinde 3 farklı kart denemeyen kullanıcıyı blokla), real-time leaderboard, IoT anomaly. Daha geniş Spark + Kafka data pipeline mimarisini de referans alabilirsiniz.
Patterns: Yaygın EDA Kalıpları
- Event Sourcing: State’i event toplamından üret (bakiye = tüm transaction’ların toplamı). Audit doğal olarak gelir.
- CQRS: Yazma ve okuma ayrı modeller. Yazma normalize, okuma denormalize materialized view.
- Saga: Distributed transaction yerine event-driven compensation. Order → Payment → Shipping zinciri.
- Outbox Pattern: DB transaction + event publish atomicity. Çift yazma anti-pattern’ini çözer.
- Change Data Capture (CDC): DB değişikliklerini Kafka’ya akıt (Debezium).
- Idempotent Consumer: Aynı event 2x işlense de aynı sonuç (event ID + state check).
- Dead Letter Topic: İşlenemeyen mesajlar ayrı topic’e, manuel inceleme.
Türkiye Özelinde EDA Dinamikleri
- Banka entegrasyonu zorluğu: BKM/Findeks gibi sistemler çoğunlukla sync REST/SOAP. Anti-corruption layer şart — Kafka topic’e adapter ile akıt.
- KVKK + PII handling: Event payload’larında TCKN/IBAN açık YASAK. Tokenization (vault’a referans) veya field-level encryption.
- e-Arşiv/e-Fatura: GIB entegrasyonları için event-driven outbox pattern çok kullanışlı; retry semantiği doğal.
- Trafik patterns: Türkiye e-ticaret peak’i 20:00-23:00, Black Friday 5-8x normal yük. Spike test mutlaka yapılmalı.
- Bulut maliyeti: AWS Frankfurt → İstanbul gecikme 50-80 ms, EU-Central üzerinden CDN + read replica makul.

Operasyonel Notlar
- Consumer lag monitoring: Burrow, Cruise Control veya Prometheus + Grafana. Lag > 10 sn ise alarm.
- Dead letter topic (DLT): İşlenemeyen mesajlar DLT’ye alınır, manuel inceleme.
- Retention disk planlaması: 7 gün × 1M msg/saat × 1 KB/msg × 3 replica = 504 GB/topic.
- Rebalancing: Consumer eklendiğinde partition’lar yeniden dağıtılır (kısa kesinti). Static membership ile minimize edilir.
- Encryption: Transit TLS, rest AES-256 (Kafka Tiered Storage ile).
- ACL: Topic/consumer group bazlı yetkilendirme (Kafka SASL/SCRAM).
- Backup: MirrorMaker 2 ile cross-region replication, ayrıca S3 sink connector ile soğuk yedek.
Anti-Pattern’ler ve Yaygın Hatalar
- Tek “events” topic: Her şey aynı topic’e — partition tasarımı çöker, consumer’lar başka domain’in mesajlarını filtrelemek zorunda.
- Event yerine command yayınlamak: “OrderShipped” event’tir; “ShipOrder” command’dır. Karıştırma producer’ı consumer’a tight-couple eder.
- Schema’sız JSON: 6 ay sonra hangi alanın opsiyonel hangisinin zorunlu olduğu hatırlanmaz.
- Çift yazma (DB + Kafka direct): Tutarsızlık kesin. Outbox veya CDC kullan.
- Idempotency check yok: Retry → duplicate fatura, duplicate ödeme.
- Çok büyük payload: 5+ MB event’ler Kafka için anti-pattern. S3’e koy, event’te referans gönder.
- Synchronous tüketim: Consumer her mesajda HTTP call yapıp 200 ms bekliyorsa throughput çöker.
Maliyet Tahminleri
| Kapasite | Self-hosted Kafka (TL/ay) | Confluent Cloud (TL/ay) | AWS MSK (TL/ay) |
|---|---|---|---|
| Düşük (10M msg/gün) | 15.000-25.000 | 22.000-35.000 | 28.000-42.000 |
| Orta (100M msg/gün) | 45.000-80.000 | 90.000-150.000 | 110.000-180.000 |
| Yüksek (1B msg/gün) | 180.000-320.000 | 450.000-800.000 | 540.000-950.000 |
Self-hosted en ucuz görünür ama operasyonel insan maliyeti (2-3 SRE) eklenmeli. Yıllık 1,5-3 milyon TL ek personel maliyeti. 100M msg/gün altındaki şirketlerde managed (Confluent, MSK, Aiven) TCO açısından genelde daha avantajlı; üzerinde self-hosted ekonomik.
Sık Sorulan Sorular
EDA mı microservice mi?
İkisi farklı kavramlar. Microservice’ler birbiriyle ya synchronous (REST/gRPC) ya asynchronous (EDA) konuşur. EDA, microservice mimarinin tipik iletişim yöntemidir. “Monolit → microservice” yolculuğunda EDA en güçlü destek. Strangler Fig pattern ile aşamalı geçişte event broker, eski monolit ile yeni servisler arasında köprü olur.
Eventual consistency müşteriyi rahatsız etmez mi?
İyi UX tasarımıyla yönetilir: optimistic UI (“siparişiniz alındı” göster, asenkron işlemeye gönder), feedback (push notification “siparişiniz hazırlanıyor”). Bankacılık gibi instant consistency gerektiren senaryolarda saga + compensation pattern.
Kafka’yı şirket içi kurmak mı yoksa managed mı?
Ekip > 5 SRE/Platform mühendisi varsa self-hosted (yıllık 30-50% tasarruf). Daha küçük ekiplerde managed (Confluent, MSK, Aiven) — operasyonel yük yok, ek personel gerekmiyor.
Schema değişikliği breaking olduğunda ne yapılır?
Üç strateji: (1) Yeni topic, eski topic deprecated; (2) Yeni event tipi (order.created.v2); (3) Tüm consumer’ları paralel olarak güncelle, sonra kademeli geçiş. Hiçbir zaman aynı topic’te breaking change yapma.
Outbox Pattern olmadan event yayınlamak mümkün mü?
Mümkün ama riskli. DB commit edilip Kafka publish başarısız olursa veri ve event tutarsız kalır. CDC (Debezium) veya Outbox’sız production senaryoları yalnızca “best-effort” senaryolar (analytics ping gibi) için kabul edilebilir.
Ömer Önal’dan pratik not: Türkiye’de event-driven mimari geçişlerinde gördüğüm en kritik hata, “önce Kafka kuralım, kullanmaya başlarız” yaklaşımıdır. Kafka altyapıdır, mimari değil. Önce event storming workshop’u yapın — domain expert + dev + product birlikte, hangi domain event’leri var, kim producer kim consumer, hangisi sync kalsın hangisi async olsun çıkartın. Sonra ilk 3 event’i Outbox Pattern ile gönderin — Kafka kurmadan önce uygulamanız “event yayınlayabilir” hâle gelsin. Geri kalan 6 ay tamamen evrim: yeni domain’lere event ekleme, yeni consumer ekleme, eski sync çağrıları async’e çevirme. Sizin ekibinizde şu an event-driven dönüşüm hangi aşamada — hiç başlamadınız mı, pilot bir domain’le mi denemeye başladınız?
Sonuç
Event-driven architecture, saatte 1M+ event işleyen modern uygulamalar için artık seçenek değil zorunluluk. Doğru tasarlanmış bir EDA (Kafka/Pulsar + Flink + Schema Registry + idempotent consumer + Outbox/Saga patterns) altyapı maliyetini %41 düşürür, p99 latency’i %58 azaltır ve yeni özellik geliştirme süresini %35 hızlandırır. EDA’yı tamamlayan mimari kararlar için gRPC vs REST vs GraphQL karşılaştırmamızı, veritabanı stratejisi için polyglot persistence rehberimizi, gözlemlenebilirlik için eBPF + Cilium ile Kubernetes ağı içeriğimizi ve performans testi için k6 + Gatling rehberimizi okumanızı öneririm. İletişim formundan projeniz için EDA mimari değerlendirme talep edebilirsiniz.
Dış otorite kaynaklar: Apache Kafka · Apache Pulsar · Confluent Engineering Blog · Martin Fowler — Event-Driven




Ömer ÖNAL
Mayıs 17, 2026Türkiye’de event-driven mimari geçişine danışmanlık verdiğim e-ticaret ve fintech ekiplerinde gözlemlediğim en kritik şey, ilk 3 ayda Kafka kurmadan başarılı pilotlar çıkartmak. Önce Outbox Pattern + scheduled worker ile domain event yayınlamayı production’a alın — broker kurmadan önce uygulama “event üretebiliyor” hale gelsin. Sonraki adımda PostgreSQL logical replication üzerinden Debezium ile CDC + Kafka entegrasyonu yapılır. Bu kademeli yaklaşımda ekip event modellemeyi öğrenir, mimari karar maliyetleri düşer ve geri dönüş kolaydır. Direkt “tamam, microservice’leri Kafka ile bağlayalım” diyen ekiplerde 6 ay sonra event format’ları, idempotency, dead letter politikası gibi temel kararların eksikliğinden ciddi production incidentler çıkıyor. Sizin sisteminizde event-driven dönüşüm hangi aşamada — pilot mu, üretim mi, yoksa hâlâ değerlendirme fazında mı?