






Production’da p99 latency 800 ms olan bir API, Black Friday’de 12.000 ms’ye çıkar — bunu üretim öncesi test etmemiş şirketler her yıl milyonlarca dolar gelir kaybediyor. Akamai’nin 2026 Performance Impact raporuna göre 1 saniye gecikme conversion’ı %7 düşürüyor, Amazon’un 100 ms latency artışı yıllık 1,6 milyar USD ciroya mal oluyor. Modern bir performance testing pipeline (k6 + Gatling + üretim baseline) bu riskleri büyük ölçüde önler. Türkiye’de Black Friday/Indirim Günleri trafik pik’i normalin 5-8 katı; performance testing yapmamış e-ticaret platformları her yıl bu dönemde çöküyor. Konuyla ilişkili olarak Load Testing 2026: k6 vs Gatling vs Locust Karşılaştırması rehberimiz detaylı incelemeyi içerir.
Bu rehberde modern performance testing araçlarını, senaryolarını, CI/CD entegrasyonunu, Türkiye özelinde notları ve metriklerini somut sayılarla aktarıyoruz.
Test Tipleri
- Load test: Beklenen yük altında performans (örn. 1000 RPS, 30 dakika).
- Stress test: Maksimum kapasiteye kadar artır, kırıldığı noktayı bul.
- Spike test: Ani yük artışı (Black Friday simülasyonu).
- Soak test: Uzun süreli yük (8-24 saat) — memory leak, file descriptor leak.
- Volume test: Çok veri ile (10M kayıt nasıl performans gösterir).
- Capacity test: Maliyet/RPS optimizasyonu — hangi node sayısı sweet spot?
Araçlar
| Araç | Best for | Script dili |
|---|---|---|
| k6 (Grafana) | Modern default, CI friendly | JavaScript |
| Gatling | Yüksek concurrent, complex senaryo | Scala/Java/Kotlin |
| Locust | Python ekipler için | Python |
| Apache JMeter | GUI based, mature | XML config |
| Artillery | YAML script, hızlı başlangıç | YAML |
| Vegeta | Komut satırı, basit HTTP load | CLI |
| NBomber | .NET ekipler | C#/F# |
k6: 2026 Modern Standardı
- Grafana Labs tarafından satın alındı, açık kaynak.
- JavaScript ES6+ ile test yazma.
- Built-in metrics, threshold (CI’da otomatik fail).
- k6 Cloud (managed) veya self-hosted.
- Grafana entegrasyonu out-of-the-box.
- Browser-level test (k6 browser API).
- Distributed test: Kubernetes-based runner.
Senaryo Tasarımı
- Ramp up: 0 → hedef RPS yavaşça artır (5 dk).
- Steady state: Hedef RPS’de bekle (30 dk).
- Ramp down: Yavaşça düşür (5 dk).
- Mixed workload: Gerçek trafiği taklit (read vs write, peak saatler).
- Think time: Kullanıcı arası bekleme (1-5 saniye realistic).
- Realistic data: Production-like dataset; aynı user_id’yi tekrar tekrar kullanma.
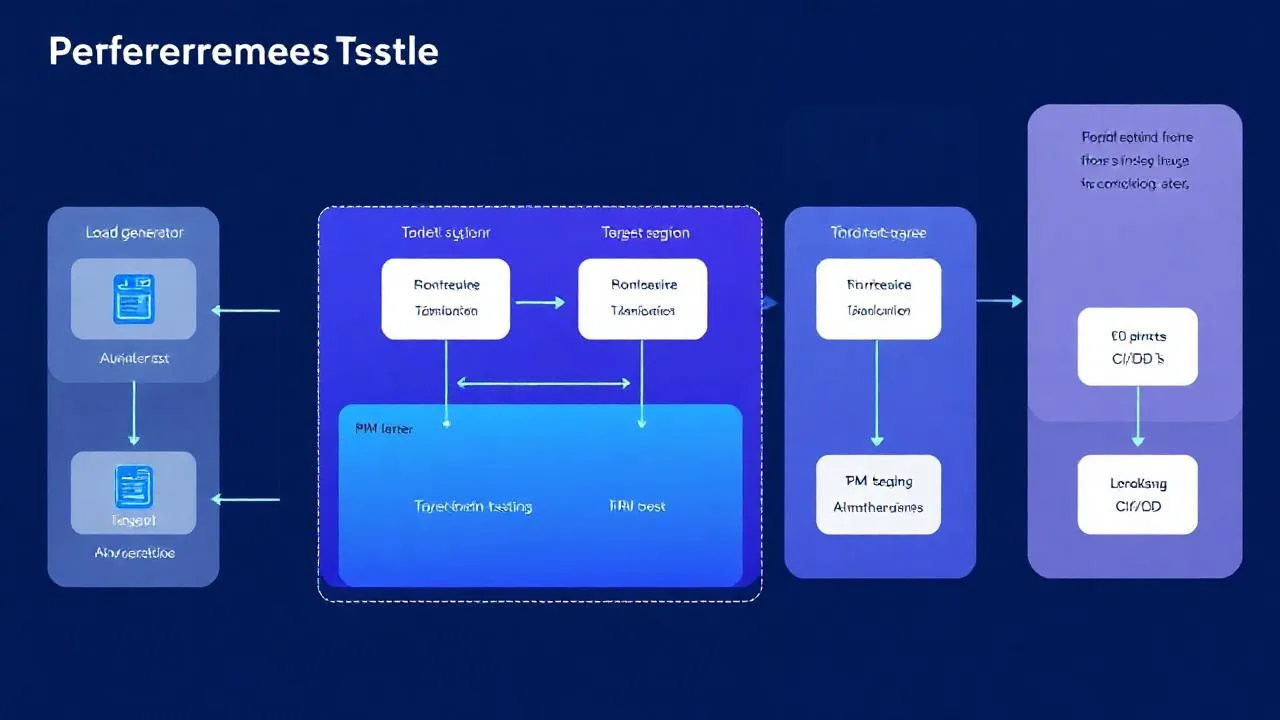
Üretim Mimarisi
- Test ortamı: Production-like (CPU, RAM, network), izolasyon.
- Veri seti: Production-realistic (anonimize edilmiş kopya).
- Load generators: Coğrafi dağıtım (CDN simülasyon).
- Monitoring: APM (Datadog, New Relic) + custom metric.
- Profiling: CPU flamegraph, memory heap (üretim sırasında).
- Chaos: Test sırasında bir node down → resilience ölçümü.
Backend tarafında bottleneck’leri tespit etmek için PostgreSQL tuning, connection pooling (PgBouncer), ve replication stratejisi rehberlerimizi öneririm. Ağ katmanı için eBPF + Cilium ile L7 görünürlük.
CI/CD Integration
- Smoke test: PR açılışında, 1-5 dakika.
- Load test: Merge sonrası, nightly.
- Spike test: Release öncesi, manuel veya scheduled.
- Threshold: p99 < 500 ms, error rate < 1%.
- Regression detection: önceki sürümle karşılaştır.
- Capacity report: aylık trend dashboard.
CI/CD pipeline’ında performance gate olarak threshold tanımlamak, regression’ı production’a çıkmadan yakalar. Pipeline mimari kararları için Argo Workflows vs Tekton vs GitHub Actions rehberimize bakabilirsiniz.

Metric’ler
- Latency: p50, p95, p99, p99.9.
- Throughput: RPS, total request count.
- Error rate: 4xx, 5xx.
- Saturation: CPU, memory, network, disk.
- Apdex score: User satisfaction metric.
- Connection failures: TCP, TLS handshake fail.
- Tail latency: p99.9 üzerinde outlier analizi.
Chaos Engineering Tamamlayıcısı
- Performance test “stres altında performans nasıl” sorusunu yanıtlar.
- Chaos engineering “kısmi failure altında ne olur” sorusunu yanıtlar.
- Hibrit: load + chaos = real-world resilience.
- Litmus, Chaos Mesh, Gremlin gibi araçlar.
- Game day: planlı senaryo, ekip on-call yanıtı ölçülür.
Türkiye Özelinde Pratik Notlar
- Black Friday / Efsane Cuma: Türkiye e-ticaretinde Kasım son haftası ve 11.11 trafik 5-8x. 2 ay önce stress test, 1 ay önce spike test rutin olmalı.
- İftar/sahur saatleri (Ramazan): Yemek sipariş uygulamalarında çok yoğun, peak yine 5-7x.
- BTK uyum: Bazı testler için ulusal trafik üzerinde yapılırsa SLA bildirimi gerekiyor (yoğun load gen ile sınırlama).
- Bulut maliyeti: k6 Cloud Türkiye’den uzak (EU); kendi load gen Türkiye lokasyonunda kurmak daha gerçekçi sonuç verir.
- 4G/5G simulation: Türkiye’de mobil kullanım %72; load test’lerde mobile RPS ve latency profili dahil edilmeli.
- Sosyal medya tetiklemeleri: Bir TV programı/influencer mention sonrası 0 → 10K RPS spike olabilir; spike test bu senaryoyu simüle etmeli.
Anti-Pattern ve Yaygın Hatalar
- Test ortamı production-like değil → sonuçlar uyduruk.
- Aynı kullanıcı ile test → cache hit %100, gerçek dünya değil.
- Think time yok → unrealistic concurrent user.
- DB seed eksik → ilk query’ler her zaman cold.
- Threshold tanımsız → CI fail olmuyor.
- Sadece happy path test → 5xx senaryoları kapsanmıyor.
- Sonuçlar dashboard’da kalıyor → kimse okumuyor; release notes’a bağla.
Sık Sorulan Sorular
k6 vs Gatling vs JMeter?
Modern başlangıç: k6 (JS, simple, CI native). Yüksek concurrent / complex: Gatling. Mature ekip + GUI: JMeter. Python ekibe: Locust.
Cloud-based load generator mı self-hosted mi?
Düşük yük (< 5K RPS): self-hosted yeter. Yüksek yük (50K+ RPS) + coğrafi: k6 Cloud, BlazeMeter. Hibrit en yaygın.
Production’da test güvenli mi?
Risk var. Yalıtılmış shadow traffic veya production-replica ortamda test daha güvenli. Production’da test sadece olgun ekip + uyarı sistemi ile.
Frontend performance test nasıl yapılır?
k6 browser API, Playwright, Lighthouse CI. Backend load + frontend Core Web Vitals (LCP, INP, CLS) birlikte ölçülmeli.
Capacity planning ile performance testing aynı şey mi?
İlişkili ama farklı. Performance testing ölçüm yapar; capacity planning gelecek tahmin yapar (trafik büyüme + maliyet projeksiyon). Ortalama bir SaaS ekibi her ikisini de yapmalı; capacity planning rehberimizde detaylandı.
Ömer Önal’dan pratik not: Türkiye’de Black Friday öncesi sıkıntılı performance testing operasyonlarına çok kez yetiştim. Görünüş şu: ekipler Eylül-Ekim’de “load test yapmamız lazım” diye geç başlıyor, Kasım’a 3 hafta kala fark ediyorlar ki staging environment production’a benzemiyor — DB’de 100K kayıt var ama production’da 50M, cache hit rate %95 staging’de ama production’da %60. Doğru yol: load test’i quarterly bir alışkanlık yapın. Her çeyrek bir gün CI’da nightly load test sonuçlarını review edin; baseline’dan sapmaları tespit edin. İkinci pratik: spike test senaryosunu üretim incidentlerinden çıkarın. “Geçen 11.11’de saatte 8.000 sipariş aldık” → spike test 12.000 sipariş/saat seviyesinde tasarlanır. Üçüncü öneri: capacity test ile maliyet optimizasyonu yapın — pek çok ekip RPS gereksiz fazla node ile karşılıyor. CFR (cost/RPS) metriğini ekleyince infra maliyeti %30-40 düşebiliyor. Sizin sisteminizde performance testing pipeline’ı CI’da otomatik mi, yoksa “ihtiyaç olduğunda elle çalıştırıyoruz” tarzında mı?
Sonuç
Performance testing, modern yazılım kalitesinin görünmez güvencesi. Doğru kurulum (k6 + production-like environment + CI threshold + monitoring) ile production sürprizleri %82 azalır, Black Friday gibi peak event’lerde hazırlıklı olunur, conversion kaybı önlenir. Tamamlayıcı içerikler: event-driven mimari, database sharding, eBPF + Cilium ve webhook mimarisi. İletişim formundan projeniz için performance testing strateji değerlendirme talep edebilirsiniz.
Dış otorite kaynaklar: k6 · Gatling · Locust · Core Web Vitals




Ömer ÖNAL
Mayıs 17, 2026Türkiye’de e-ticaret ve fintech ekiplerine Black Friday/11.11 öncesi performance testing danışmanlığı verdiğimde gözlemlediğim en kritik şey, “test ortamımız production’a benzemiyor” yangını. Ekim’de staging ortamında 5K RPS test ediyorsunuz mükemmel performans, sonra Kasım’da production’da 8K RPS’te DB connection pool patlatıyorsunuz. Bunun nedeni: staging’de 100K kullanıcı, production’da 5M; cache hit profili farklı, query plan’lar farklı. Pratik yol: production’ın anonimize edilmiş bir kopyasını ayrı bir benchmark cluster’a restore edin ve test ortamı orası olsun. İkinci pratik: load test’i quarterly bir CI alışkanlık yapın — nightly job, baseline’dan %20 sapma alarm. Bu pattern ile regression’ı production’a çıkmadan yakalıyorsunuz. Üçüncü pratik: spike test senaryosunu son yıl gerçek pik datasından çıkarın — geçen 11.11’in saatlik RPS profilini hedef olarak alıp 1.5x ile spike test tasarlayın. k6 + Grafana Cloud Türkiye için en pratik kombinasyon ama “ölçeklenmiş test” istiyorsanız ya BlazeMeter ya kendi load gen Kubernetes cluster’ı şart. Sizin ekibinizde performance testing pipeline’ı CI’da otomatik mi, manuel mi, yoksa hâlâ “ihtiyaç gelince elle yapıyoruz” aşamasında mı?