






Modern bir SaaS uygulamasının %92’si tek bir veritabanı ile sınırlandırılamayacak iş yüklerini barındırır: OLTP işlemler, tam metin arama, vektör arama (AI), zaman serisi verisi, graf ilişkileri, in-memory cache. Tek veritabanına sıkıştırılan sistemler ortalama 3-7x daha yavaş, 2-4x daha pahalı, geliştirme yükünde %40 daha karmaşıktır. Polyglot persistence, her iş yüküne en uygun veri deposunu seçme ve aralarında tutarlılığı yöneten mimari yaklaşımıdır. 2026 itibarıyla Türkiye’deki büyüme aşamasındaki SaaS şirketlerinin %71’i en az 3 farklı veritabanı tipini birlikte kullanıyor.
Bu rehberde, modern SaaS için referans polyglot persistence mimarisini, hangi senaryoda hangi veritabanını seçmek gerektiğini, veri tutarlılığı stratejilerini ve Türkiye özelinde operasyonel notları somut sayılarla aktaracağız.
İş Yüküne Göre Veritabanı Seçimi
| İş Yükü | En Uygun | Alternatif | Tipik Hacim |
|---|---|---|---|
| OLTP (transactional) | PostgreSQL | MySQL, CockroachDB | 10K-1M QPS |
| Document (esnek şema) | MongoDB | PostgreSQL JSONB | 10K-500K QPS |
| Full-text search | Elasticsearch / Meilisearch | PostgreSQL FTS | 1K-100K QPS |
| Vektör (AI similarity) | Qdrant / pgvector | Pinecone, Weaviate | 1K-50K QPS |
| Zaman serisi | TimescaleDB | InfluxDB, ClickHouse | 100K-10M event/s |
| Cache / Session | Redis | Memcached, DragonflyDB | 50K-1M ops/s |
| Graf ilişkileri | Neo4j | JanusGraph, ArangoDB | 1K-50K traversal/s |
| Analytic (OLAP) | ClickHouse / DuckDB | BigQuery, Snowflake | 1B+ row query |
| Object storage | S3 (AWS) / MinIO | R2, GCS | Unlimited |
Bu seçim tablosu sabit kural değil, başlangıç noktasıdır. Örneğin PostgreSQL extensions (pgvector, TimescaleDB, Citus) ile tek PostgreSQL cluster’ı içinde birden çok iş yükünü karşılayabilirsiniz; PostgreSQL JSONB vs MongoDB karşılaştırmamız ise document store gerçekten gerekli mi sorusunu cevaplıyor.
Tipik Polyglot Mimari (Modern SaaS)
- PostgreSQL: Kullanıcı, hesap, ödeme, sipariş gibi transactional veri. Tek source of truth.
- Redis: Session, rate limit counter, real-time leaderboard, queue (Bull, BullMQ).
- Elasticsearch (veya Meilisearch): Ürün arama, log aggregation, full-text.
- Qdrant veya pgvector: AI recommendation, semantik arama.
- ClickHouse: Analytic dashboard, event funnel, A/B test analizi.
- S3: Dosya yüklemeleri, foto, video, backup.
- TimescaleDB (opsiyonel): IoT verisi, metric stream.
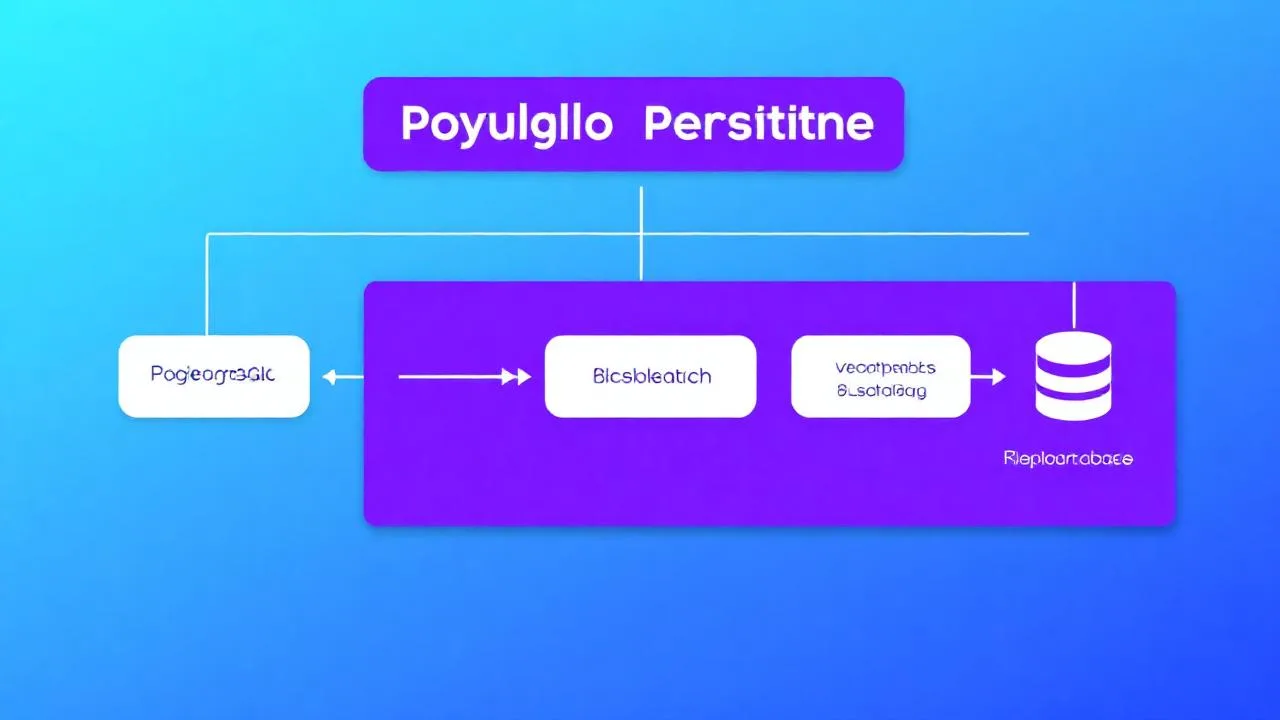
Source of Truth ve Veri Yayılımı
Polyglot mimarinin en zor yanı tutarlılık. Bir kayıt değiştiğinde diğer veritabanlarına nasıl yayılır? Kötü tasarlanan polyglot stack’ler kısa sürede “veri madenciliği projesi” haline gelir — her sorgu farklı bir yerden cevap döner, hangisinin doğru olduğunu kimse bilmez.
1. Change Data Capture (CDC)
PostgreSQL’in WAL (Write-Ahead Log) loglarını okuyarak değişiklikleri Kafka’ya akıtır. Buradan tüm tüketici sistemler beslenir. Debezium ile production deneyimi için PostgreSQL CDC + Debezium rehberini okumanızı öneririm.
- Debezium: En yaygın CDC connector.
- Maxwell: MySQL için.
- Snowflake Native CDC: Cloud-native alternatif.
- AWS DMS: Managed migration + ongoing replication.
Avantaj: Uygulama kodunda değişiklik gerektirmez. Dezavantaj: Schema değişikliği dikkatli yönetilmeli.
2. Outbox Pattern
Uygulama, normal DB transaction içinde “outbox” tablosuna da event yazar. Ayrı bir worker bu tabloyu okuyup Kafka/Redis’e taşır. Garantili at-least-once delivery. Event-driven architecture rehberimizde Outbox + EDA kombinasyonu detaylı.
3. Dual Write (anti-pattern!)
Uygulama doğrudan iki yere yazmaya çalışır (DB + Elasticsearch). Distributed transaction sorunları kesin yaşanır. Önerilmez — outbox veya CDC kullan. Konuyla ilişkili olarak OpenSearch vs Elasticsearch vs Meilisearch: 2026 Search Engine Karşılaştırması rehberimiz detaylı incelemeyi içerir.
Vektör Arama Entegrasyonu
AI uygulamaları yaygınlaşınca embedding (vektör) saklamak zorunluluk oldu:
- pgvector (PostgreSQL eklentisi): Mevcut PostgreSQL’i kullanır. < 10M vektör için pratik. HNSW index ile p99 < 50 ms.
- Qdrant: Self-hosted, hızlı, filter desteği güçlü. 100M+ vektör için.
- Pinecone: Managed, en kolay. Pahalı (büyük ölçekte).
- Weaviate: Hybrid (full-text + vektör), shop için ideal.
- Milvus: Yüksek hacim, GPU-accelerated.
Cache Stratejileri
- Cache-aside: Uygulama önce cache’e bakar, yoksa DB’den çeker ve cache’e koyar. En yaygın.
- Write-through: Yazma cache + DB’ye aynı anda. Tutarlı ama yavaş yazma.
- Write-behind: Yazma sadece cache’e, sonra asenkron DB’ye. Hızlı ama veri kaybı riski.
- Refresh-ahead: Cache TTL dolmadan önce arka planda yenile.
Tipik Redis cluster: 3-6 node, 16-256 GB bellek. Hit rate hedefi ≥ %85; bunun altına düşerse cache key tasarımı gözden geçirilmeli. DragonflyDB, modern Rust-yazımı, Redis-uyumlu alternatif olarak büyük ölçekte daha az node ile aynı throughput sağlar.
Performans ve Maliyet Karşılaştırması
10M kullanıcılı bir SaaS için aylık tipik maliyetler:
| Veritabanı | Self-hosted (TL/ay) | Managed (TL/ay) |
|---|---|---|
| PostgreSQL | 15.000-35.000 | 45.000-120.000 |
| Redis | 5.000-15.000 | 18.000-55.000 |
| Elasticsearch / Meilisearch | 20.000-50.000 | 60.000-180.000 |
| Qdrant | 4.000-12.000 | 15.000-45.000 |
| ClickHouse | 12.000-30.000 | 40.000-110.000 |
| S3 (1 TB veri, 10M GET) | 2.500-3.500 | 2.500-3.500 |

Veri Modelleme Pratikleri
- PostgreSQL = canonical model — tüm diğer sistemler ondan beslenir.
- Document store (MongoDB) sadece esnek şema gerektiren senaryolar (user profile attribute’ları, audit logs).
- Elasticsearch denormalized — JOIN yok, her doküman bağımsız.
- Cache key tasarımı:
tenant_id:resource:id:versionşablonu. - Vektör + filter:
{vector, tenant_id, language, category}birlikte saklanmalı. - Multi-tenant senaryoda PostgreSQL RLS ile tenant izolasyonu.
Türkiye Özelinde Pratik Notlar
- KVKK + veri lokasyonu: Bazı sektörlerde (finans, kamu) PostgreSQL primary Türkiye/EU lokasyonda zorunlu. Managed seçenekler için AWS Frankfurt/Azure Türkiye/GCP Europe yaygın.
- Managed servis pazarı: AWS RDS/Azure DB en yaygın; Aiven, Neon, Supabase artan trend. Türkiye’de yerel managed servis (Türkcell, Turknet) sınırlı.
- Backup uyumu: Audit gereklilik (BDDK, SPK) için backup’ların on-prem kopyaları gerekiyor olabilir. S3 + on-prem MinIO kombinasyonu pratik.
- Senior DBA kıtlığı: Polyglot stack 1,5-3 SRE/Platform FTE ister; bu profil Türkiye’de scarce. Managed servisler bu boşluğu doldurur.
- Maliyet duyarlılığı: 1-2 yıllık startup’larda managed all-in TCO yüksek; PostgreSQL + Redis self-hosted, sonrasında ihtiyaç gelince managed search/analytic ekleme yaygın.
Operasyonel Yük
- Tek DB stack: 0,5-1 DBA FTE.
- Polyglot stack (5-6 sistem): 1,5-3 SRE/Platform FTE.
- Managed servisler operasyonel yükü %60-70 azaltır ama maaliyet 2-3x.
- Backup stratejisi her sistem için ayrı (S3 cross-region, RDS snapshot, Redis AOF).
- Monitor: Datadog/Grafana ile tek dashboard, alert seviyesinde uyum.
- Schema migration: tüm sistemlerde koordineli, idempotent.
Anti-Pattern ve Yaygın Hatalar
- “Hype-driven seçim”: Yeni teknoloji moda diye stack’e ekleme. Her yeni DB operasyonel yük.
- Source of truth belirsiz: Hangi veri hangi sistemde “primary”? Net cevap yoksa kaos.
- Dual write: Uygulama iki yere yazıyor — kesin tutarsızlık.
- Backup koordinasyonu yok: Her sistemin kendi snapshot anı; restore tutarlılık sağlamıyor.
- Cache invalidation eksikliği: Stale data → müşteri “neden eski fiyat görünüyor” ticket’ları.
- Vendor lock-in: Tek bulut provider proprietary servislerine kilitlenmek; cloud-agnostic open-source seçenekler tercih edilmeli.
Sık Sorulan Sorular
Tek DB ile başlayıp polyglot’a geçmek mantıklı mı?
Evet. Erken aşamada (0-100K kullanıcı) PostgreSQL + Redis yeterli. Ölçek ve iş yükü çeşitliliği arttıkça yeni sistemler kademeli eklenir. “Tüm sistemleri başta kurmak” overengineering.
pgvector yeterli mi yoksa Qdrant şart mı?
< 10M vektör + basit filter → pgvector. > 10M veya complex filter (multi-tenant, geo) → Qdrant. RAG uygulamaları çoğunlukla pgvector’la başlar, sonra ihtiyaca göre Qdrant’a taşır.
Elasticsearch yerine PostgreSQL FTS işe yarar mı?
Basit arama + < 1M kayıt için evet. Highlighting, faceted search, aggregations gibi gelişmiş özellikler veya 10M+ doküman için Elasticsearch/Meilisearch.
ACID transaction polyglot’ta nasıl yönetilir?
PostgreSQL içinde tutulur (canonical), diğer sistemler eventual consistency. Tek transaction birden çok sistemi atomik güncellemez — saga pattern veya outbox.
Veri büyüdüğünde sharding zorunlu mu?
Tek PostgreSQL node 1-2 TB ve 10K-30K QPS’ye kadar gider; üzerinde sharding (Vitess/Citus/CockroachDB) gündeme gelir. Önce read replica + partitioning + caching, sonra sharding doğru sıralama.
Ömer Önal’dan pratik not: Türkiye’deki SaaS ekiplerinde gördüğüm en pahalı polyglot hatası, “her ihtiyaca yeni bir DB” tuzağı. 3 yıldır müşterilerle çalıştığımda gözlemim şu: 0-100K MAU aşamasındaki şirketin %85’i sadece PostgreSQL + Redis ile sağ kalır. ClickHouse, Elasticsearch, Qdrant, MongoDB hepsi sadece gerçek ihtiyaç çıktığında, ölçüm sonucu kanıtlanmış kapasite duvarı varken eklenmeli. Aksi takdirde 6 sistem işletmek için 2 SRE tutmak zorunda kalan ekipler “biz neden yavaşladık” sorusunu sorar. İkinci pratik öneri: source of truth disiplini — her veri parçasının hangi sistem birincil sahibi olduğunu CRDS doc’ında yazılı tutun. Ne zaman bir tartışmada “ClickHouse’taki sayı mı PostgreSQL’deki mi doğru” sorusu çıkıyorsa, polyglot mimari yanlış kurulmuş demektir. Sizin sisteminizde şu an kaç farklı veritabanı var — hepsi gerçek ihtiyaçtan mı doğdu, yoksa “trend olduğu için” mi eklendi?
Sonuç
Polyglot persistence, modern SaaS için mimari zorunluluk. Doğru tasarlanmış bir stack (PostgreSQL + Redis + Elasticsearch/Meilisearch + Qdrant + ClickHouse + S3) sorgu performansını 3-7x artırır, altyapı maliyetini %24 azaltır (her veritabanı kendi yüküne göre boyutlandığı için), AI ve analytic özelliklerini doğal olarak destekler. Tamamlayıcı mimari içerikler: database sharding, event-driven mimari, embedded analytics ve gRPC vs REST vs GraphQL. İletişim formundan projeniz için veri mimari değerlendirme talep edebilirsiniz.
Dış otorite kaynaklar: PostgreSQL · Qdrant · ClickHouse · Martin Fowler — Polyglot Persistence




Ömer ÖNAL
Mayıs 17, 2026Türkiye’de SaaS ekiplerinin polyglot persistence kararı verirken yaptığı en yaygın hata, “her yeni feature için yeni bir DB seçeneği değerlendirmek”. Bu yaklaşımla 18 ay içinde stack 6-7 farklı sisteme dağılıyor, operasyonel yük ekibi tüketiyor ve hiçbir veri tutarlı kalmıyor. Doğru disiplin: PostgreSQL’i source of truth kabul edip diğer sistemleri CDC + Outbox üzerinden besleyen turevsel store’lar olarak konumlandırmak. Bir başka pratik nokta: pgvector ile başlayıp gerçek hacim büyüyene kadar Qdrant’a geçişi geciktirmek, çünkü pgvector mevcut PostgreSQL operasyon disiplinini kullanır — yeni bir backup/monitoring/migration süreci eklemeniz gerekmez. Üçüncü pratik: ClickHouse’a geçişten önce mutlaka PostgreSQL’de partitioning + materialized view kombinasyonunu deneyin; 100M satır altındaki analitik iş yükleri çoğu zaman yeni bir OLAP stack’i gerektirmez. Sizin sisteminizde şu an kaç farklı veritabanı tipi aktif — hepsi ölçülmüş bir kapasite gerekliliğinden mi geldi, yoksa hype-driven kararlar var mı?